
Linux/390 - Notes and Observations


|
|
Linux/390 - Notes and Observations |
|
|
|
Abstract
This document is a collection of extracts, observations and notes pertaining to the S/390 port of Linux.
Contents
![]()
On December 18, 1999, IBM published its modifications and additions to the Linux 2.2.13 code base for the support of the S/390 architecture. This port is designed to run under VM/ESA and natively. The code has subsequently been rolled into the 2.2.15 level.
This document contains information specific to the S/390 port of Linux. In it I have reproduced documentation found within the distribution that describes the I/O facilities and DASD handling. In addition, information that I have come across as I have looked at the port such as new source files, system calls, and register conventions have been included.
![]()
The following section was copied from the
Documentation/390 directory of the Linux distribution. It was written by Indo Adlung and is copyright IBM 1999, under the GNU Public License.
This chapter describes the common device support routines for Linux/390. Different than other hardware architectures, ESA/390 has defined a unified I/O access method. This gives relief to the device drivers as they don't have to deal with different bus types, polling versus interrupt processing, shared versus non-shared interrupt processing, DMA versus port I/O (PIO), and other hardware features more. i However, this implies that either every single device driver needs to implement the hardware I/O attachment functionality itself, or the operating system provides for a unified method to access the hardware, providing all the functionality that every single device driver would have to provide itself.
The document does not intend to explain the ESA/390 hardware architecture in every detail. This information can be obtained from the ESA/390 Principles of Operation manual (IBM Form. No. SA22-7201).
In order to build common device support for ESA/390 I/O interfaces, a functional layer was introduced that provides generic I/O access methods to the hardware. The following figure shows the usage of the common device support of Linux/390 using a TCP/IP driven device access an example. Similar figures could be drawn for other access methods, e.g. file system access to disk devices.
The common device support layer shown above comprises the I/O support routines defined below. Some of them implement common Linux device driver interfaces, while some of them are ESA/390 platform specific.
allow a device driver to determine the devices attached (visible) to the system and their current status.
get IRQ (subchannel) from device number and vice versa.
read device characteristics
obtain ownership for a specific device.
release ownership for a specific device.
disable a device from presenting interrupts.
enable a device, allowing for I/O interrupts.
initiate an I/O request.
terminate the current I/O request processed on the device.
generic interrupt routine. This function is called by the interrupt entry routine whenever an I/O interrupt is presented to the system. The do_IRQ() routine determines the interrupt status and calls the device specific interrupt handler according to the rules (flags) defined during I/O request initiation with do_IO().
The next sections describe the functions, other than
do_IRQ() in more details. The do_IRQ() interface is not described, as it is called from the Linux/390 first level interrupt handler only and does not comprise a device driver callable interface. Instead, the functional description of do_IO() also describes the input to the device specific interrupt handler.
The following chapters describe the I/O related interface routines the Linux/390 common device support (CDS) provides to allow for device specific driver implementations on the IBM ESA/390 hardware platform. Those interfaces intend to provide the functionality required by every device driver implementation to allow driving a specific hardware device on the ESA/390 platform. Some of the interface routines are specific to Linux/390 and some of them can be found on other Linux platforms' implementations too.
Miscellaneous function prototypes, data declarations, and macro definitions can be found in the architecture specific "C header file"
linux/arch/s390/kernel/IRQ.h.
Different to other hardware platforms, the ESA/390 architecture does not define interrupt lines managed by a specific interrupt controller and bus systems that may or may not allow for shared interrupts, DMA processing, etceteras. Instead, the ESA/390 architecture has implemented a so-called channel subsystem, which provides a unified view of the devices physically attached to the systems. Though the ESA/390 hardware platform knows about a huge variety of different peripheral attachments like disk devices (also known as DASD), tapes, communication controllers, they can all by accessed by a well defined access method and they are presenting I/O completion a unified way: I/O interruptions. Every single device is uniquely identified to the system by a so-called subchannel, where the ESA/390 architecture allows for 64k devices to be attached.
Linux, however was first built on the Intel PC architecture, with its two cascaded 8259 programmable interrupt controllers (PICs), that allow for a maximum of 15 different interrupt lines. All devices attached to such a system share those 15 interrupt levels. Devices attached to the ISA bus system must not share interrupt levels (also known as IRQs), as the ISA bus bases on edge triggered interrupts. MCA, EISA, PCI and other bus systems base on level triggered interrupts, and thus allow for shared IRQs. However, if multiple devices present their hardware status by the same (shared) IRQ, the operating system has to call every single device driver registered on this IRQ in order to determine the device driver owning the device that raised the interrupt.
In order not to introduce a new I/O concept to the common Linux code, Linux/390 preserves the IRQ concept and semantically maps the ESA/390 subchannels to Linux as IRQs. This allows Linux/390 to support up to 64k different IRQs, uniquely representig a single device each.
During its startup the Linux/390 system checks for peripheral devices. A so-called "subchannel" uniquely defines each of those devices by the ESA/390 channel subsystem. While the subchannel numbers are system generated, each subchannel also takes a user-defined attribute, the so-called "device number". Both, subchannel number and device number can not exceed 65535. The
init_IRQ() routine gathers the information about control unit type and device types that imply specific I/O commands (channel command words or CCWs) in order to operate the device. Device drivers can retrieve this set of hardware information during their initialization step to recognize the devices they support using get_dev_info_by_IRQ() or get_dev_info_by_devno() respectively.
This methods implies that Linux/390 does not require to probe for free (not armed) interrupt request lines (IRQs) to drive its devices with. Where applicable, the device drivers can use the
read_dev_chars() to retrieve device characteristics. This can be done without having to request device ownership previously.
When a device driver has recognized a device it wants to claim ownership for, it calls
request_IRQ() with the device's subchannel id serving as pseudo IRQ line. One of the required parameters it has to specify is dev_id, defining a device status block, the CDS layer will use to notify the device driver's interrupt handler about interrupt information observed. It depends on the device driver to properly handle those interrupts.
In order to allow for easy I/O initiation the CDS layer provides a
do_IO() interface that takes a device specific channel program (one or more CCWs) as input sets up the required architecture specific control blocks and initiates an I/O request on behalf of the device driver. The do_IO() routine allows for different I/O methods, synchronous and asynchronous, and allows to specify whether it expects the CDS layer to notify the device driver for every interrupt it observes, or with final status only. It also provides a scheme to allow for overlapped I/O processing. See "2.9 do_IO() - Initiate I/O Request" on page * for more details. A device driver must never issue ESA/390 I/O commands itself, but must use the Linux/390 CDS interfaces instead.
For long running I/O request to be canceled, the CDS layer provides the
halt_IO() function. Some devices require to initially issue a HALT SUBCHANNEL (HSCH) command without having pending I/O requests. This function is also covered by halt_IO().
When done with a device, the device driver calls
free_IRQ() to release its ownership for the device. During free_IRQ() processing the CDS layer also disables the device from presenting further interrupts: the device driver does not need to assure it. The device will be re-enabled for interrupts with the next call to request_IRQ().
During system startup -
init_IRQ() processing - the generic I/O device support checks for the devices available. For all devices found it collects the Sense-ID information. For those devices supporting the command it also obtains extended Sense-ID information.
int get_dev_info_by_IRQ( int IRQ, dev_info_t *devinfo); int get_dev_info_by_devno( unsigned int IRQ, dev_info_t *devinfo);
|
|
Defines the subchannel, status information is to be returned for. |
|
device number. |
|
Pointer to a user buffer of type dev_info_t that should be filled with device specific information. |
typedef struct {
unsigned int devno; /* device number */
unsigned int status; /* device status */
senseid_t sid_data; /* senseID data */
} dev_info_t;
|
|
Device number as configured in the IOCDS |
|
device status |
|
data obtained by a SenseID call |
Possible status values are:
DEVSTAT_NOT_OPER - device was found not operational. In this case the caller should disregard the sid_data buffer content.
//
// SenseID response buffer layout
//
typedef struct {
/* common part */
unsigned char reserved; /* always 0x'FF' */
unsigned short cu_type; /* control unit type */
unsigned char cu_model; /* control unit model */
unsigned short dev_type; /* device type */
unsigned char dev_model; /* device model */
unsigned char unused; /* padding byte */
/* extended part */
ciw_t ciw[62]; /* variable # of CIWs */
} senseidThe ESA/390 I/O architecture defines certain device specific I/O functions. The device returns the device specific command code together with the Sense-ID data in so called Command Information Words (CIW):
typedef struct _ciw {
unsigned int et : 2; // entry type
unsigned int reserved : 2; // reserved
unsigned int ct : 4; // command type
unsigned int cmd : 8; // command
unsigned int count : 16; // count
} ciw_t;
Possible CIW entry types are:
#define CIW_TYPE_RDC 0x0; // read configuration data
#define CIW_TYPE_SII 0x1; // set interface identifier
#define CIW_TYPE_RNI 0x2; // read node identifier
The device driver may use these commands as appropriate.
The
get_dev_info_by_IRQ() / get_dev_info_by_devno() functions return:
|
0 |
Sucessful completion |
|
-ENODEV |
IRQ or devno don't specify a known subchannel or device number. |
|
-EINVAL |
Invalid devinfo value. |
In order to scan for known devices a device driver should scan all IRQs by calling
get_dev_info() until it returns -ENODEV as there are not any more available devices.
If a device driver wants to request ownership for a specific device it must call
request_IRQ() prior to be able to issue any I/O request for it, including above mentioned device dependent commands.
Please see the "ESA/390 Common I/O-Commands and Self Description" manual, with IBM form number SA22-7204 for more details on how to read the Sense-ID output, CIWs and device independent commands.
While some device drivers act on the IRQ (subchannel) only, others take user defined device configurations on device number base, according to the device numbers configured in the IOCDS. The following routines serve the purpose to convert IRQ values into device numbers and vice versa.
int get_IRQ_by_devno( unsigned int devno ); unsigned int get_devno_by_IRQ( int IRQ );
The functions return :
This routine returns the characteristics for the device specified.
The function is meant to be called without an IRQ handler being in place. However, the IRQ for the requested device must not be locked or this will cause a deadlock situation. Further, the driver must assure that nobody else has claimed ownership for the requested IRQ yet or the owning device driver's internal accounting may be affected.
In case of a registered interrupt handler, the interrupt handler must be able to properly react on interrupts related to the
read_dev_chars() I/O commands. While the request is processed synchronously, the device interrupt handler is called for final ending status. In case of error situations the interrupt handler may recover appropriately. The device IRQ handler can recognize the corresponding interrupts by the interruption parameter being 0x00524443. If using the function with an existing device interrupt handler in place, the IRQ must be locked prior to call read_dev_chars().
The function may be called enabled or disabled.
int read_dev_chars( int IRQ, void **buffer, int length );
|
|
specifies the subchannel the device characteristic retrieval is requested for |
|
pointer to a buffer pointer. The buffer pointer itself may be NULL to have the function allocate a buffer or must contain a valid buffer area. |
|
length of the buffer provided or to be allocated. |
The read_dev_chars() function returns :
|
0 |
Successful completion |
|
-ENODEV |
IRQ does not specify a valid subchannel number |
|
-EINVAL |
An invalid parameter was detected |
|
-EBUSY |
An irrecoverable I/O error occurred or the device is not operational |
The function can be used in two ways:
read_dev_chars() allocates a data buffer and provides the device characteristics together. It is the caller's responsibility to release the kernel memory if not longer needed. This behavior is triggered by specifying a NULL buffer area (*buffer == NULL).
In either case the caller must provide the data area length: for the buffer specified or the buffer wanted allocated.
As previously discussed a device driver will scan for the devices its supports by calling
get_dev_info(). Once it has found a device it will call request_IRQ() to request ownership for it. This call causes the subchannel to be enabled for interrupts if it was found operational.
int request_IRQ( unsigned int IRQ, int (*handler)( int, void *, struct pt_regs *), unsigned long irqflags, const char *devname, void *dev_id);
|
|
Specifies the subchannel the ownership is requested for |
|
Specifies the device driver's interrupt handler to be called for interrupt processing |
|
IRQ flags, must be 0 (zero) or SA_SAMPLE_RANDOM |
|
Device name |
|
Required pointer to a device specific buffer of type devstat_t |
typedef struct {
unsigned int devno; /* device number from irb */
unsigned int intparm; /* interrupt parameter */
unsigned char cstat; /* channel status - accumulated */
unsigned char dstat; /* device status - accumulated */
unsigned char lpum; /* last path used mask from irb */
unsigned char unused; /* not used - reserved */
unsigned int flag; /* flag : see below */
unsigned long cpa; /* CCW addr from irb at prim. status */
unsigned int rescnt; /* count from irb at primary status */
unsigned int scnt; /* sense count, if available */
union {
irb_t irb; /* interruption response block */
sense_t sense; /* sense information */
} ii; /* interrupt information */
} devstat_t;
During
request_IRQ() processing, the devstat_t layout does not matter as it won't be used during request_IRQ() processing. See "2.9 do_IO() - Initiate I/O Request" on page * for a functional description of its usage.
The
request_IRQ() function returns :
|
0 |
Successful completion |
|
-EINVAL |
An invalid parameter was detected |
|
-EBUSY |
Device (subchannel) already owned |
|
-ENODEV |
The device is not operational |
|
-ENOMEM |
Not enough kernel memory to process request |
While Linux for Intel defines dev_id as a unique identifier for shared interrupt lines it has a totally different purpose on Linux/390. Here it serves as a shared interrupt status area between the generic device support layer, and the device specific driver. The value passed to
request_IRQ() must therefore point to a valid devstat_t type buffer area the device driver must preserve for later usage. That is, it must not be released prior to a call to free_IRQ().
The only value parameter irqflags supports is SA_SAMPLE_RANDOM if appropriate. The Linux/390 kernel does not know about "fast" interrupt handlers, or does it allow for interrupt sharing. Remember, the term interrupt level (IRQ), device, and subchannel are used interchangeably in Linux/390.
If
request_IRQ() was called in enabled state, or if multiple CPUs are present, the device may present an interrupt to the specified handler prior to request_IRQ() return to the caller already. This includes the possibility of unsolicited interrupts or a pending interrupt status from an earlier solicited I/O request. The device driver must be able to handle this situation properly or the device may become non-operational.
Although the interrupt handler is defined to be called with a pointer to a struct pt_regs buffer area, this is not implemented by the Linux/390 generic I/O device driver support layer. The device driver's interrupt handler must therefore not rely on this parameter on function entry.
A device driver may call
free_IRQ() to release ownership of a previously acquired device.
void free_IRQ( unsigned int IRQ, void *dev_id);
|
|
Specifies the subchannel the ownership is requested for |
|
Required pointer to a device specific buffer of type devstat_t. This must be the same as the one specified during a previous call to request_IRQ(). |
Unfortunately
free_IRQ() is defined not to return error codes. That is, if called with wrong parameters a device may still be operational although there is no device driver available to handle its interrupts. Further, during free_IRQ() processing we may possibly find pending interrupt conditions. As those need to be processed, we have to delay free_IRQ() returning until a clean device status is found by synchronously handling them.
The call to
free_IRQ() will also cause the device (subchannel) be disabled for interrupts. The device driver must not release any data areas required for interrupt processing prior to free_IRQ() return to the caller as interrupts can occur prior to free_IRQ() returning. This is also true when called in disabled state if either multiple CPUs are presents or a pending interrupt status was found during free_IRQ() processing.
This function may be called at any time to disable interrupt processing for the specified IRQ. However, as Linux/390 maps IRQs to the device (subchannel) one-to-one, this may require more extensive I/O processing than anticipated, especially if an interrupt status is found pending on the subchannel that requires synchronous error processing.
int disable_IRQ( unsigned int IRQ );
|
|
Specifies the subchannel to be disabled |
The disable-IRQ() routine may return:
|
0 |
Successful completion |
|
-EBUSY |
Device (subchannel) already owned |
|
-ENODEV |
The device is not operational or the IRQ does not specify a valid subchannel |
Unlike the Intel based hardware architecture the ESA/390 architecture does not have a programmable interrupt controller (PIC) where a specific interrupt line can be disabled. Instead the subchannel logically representing the device in the channel subsystem must be disabled for interrupts. However, if there are still interrupt conditions pending they must be processed first in order to allow for proper processing after re-enabling the device at a later time. This may lead to delayed disable processing.
As described previously the disable processing may require extensive processing. Therefore disabling and re-enabling the device using
disable_IRQ() or enable_IRQ() should be avoided and is not suitable for high frequency operations.
Linux for Intel defines this function
void disable_IRQ( int IRQ);
This is suitable for the Intel PC architecture as this only causes to mask the requested IRQ line in the PIC which is not applicable for the ESA/390 architecture. Therefore we allow for returning error codes.
This function is used to enable a previously disabled device (subchannel). See "2.7 disable_IRQ() - Disable Interrupts for a given Device" on page
* for more details.int enable_IRQ( unsigned int IRQ );
|
|
Specifies the subchannel to be enabled |
The
enable-IRQ() routine may return:
|
|
Successful completion |
|
Device (subchannel) busy, which implies the device is already enabled |
|
The device is not operational or the IRQ does not specify a valid subchannel |
The
do_IO() routines is the I/O request front-end processor. All device driver I/O requests must be issued using this routine. A device driver must not issue ESA/390 I/O commands itself. Instead the do_IO() routine provides all interfaces required to drive arbitrary devices.
This description also covers the status information passed to the device driver's interrupt handler as this is related to the rules (flags) defined with the associated I/O request when calling
do_IO().
int do_IO( int IRQ, ccw1_t *cpa, unsigned long intparm, unsigned int lpm, unsigned long flag);
|
|
IRQ (subchannel) the I/O request is destined for |
|
Logical start address of channel program |
|
User-specific interrupt information; will be presented back to the device driver's interrupt handler. Allows a device driver to associate the interrupt with a particular I/O request. |
|
Defines the channel path to be used for a specific I/O request. Valid with flag value of DOIO_VALID_LPM only. |
|
Defines the action to be performed for I/O processing |
Possible flag values are:
|
|
Allow for early interrupt notification |
|
LPM input parameter is valid (see usage notes for details) |
|
Wait synchronously for final status |
|
Report all interrupt conditions |
The cpa parameter points to the first format 1 CCW of a channel program:
typedef struct {
char cmd_code; /* command code */
char flags; /* flags, like IDA addressing, etc. */
unsigned short count; /* byte count */
void *cda; /* data address */
} ccw1_t __attribute__ ((aligned(8)));
with the following CCW flags values defined:
|
|
Data chaining |
|
Command chaining |
|
Suppress incorrect length |
|
Skip |
|
PCI |
|
Indirect addressing |
|
Suspend |
The
do_IO() function returns:
|
|
Successful completion or request successfully initiated |
|
The do_io() function was called out of sequence. The device is currently processing a previous I/O request |
|
IRQ does not specify a valid subchannel, the device is not operational (check dev_id.flags) or the IRQ is not owned. |
|
Both DOIO_EARLY_NOTIFICATION and DOIO_REORT_ALL flags have been specified. The usage of those flags is mutual exclusive. |
When the I/O request completes, the CDS first level interrupt handler will setup the dev_id buffer of type devstat_t defined during
request_IRQ() processing. See "2.5 request_IRQ() - Request Device Ownership" on page * for the devstat_t data layout. The dev_id->intparm field in the device status area will contain the value the device driver has associated with a particular I/O request. If a pending device status was recognized dev_id->intparm will be set to 0 (zero). This may happen during I/O initiation or delayed by an alert status notification.
In any case this status is not related to the current (last) I/O request. In case of a delayed status notification no special interrupt will be presented to indicate I/O completion as the I/O request was never started, even though
do_IO() returned with successful completion.
Possible
dev_id->flag values are:
|
|
Sense data is available |
|
Device is not operational |
|
Interrupt is presented as a result of a call to do_IO() |
|
Interrupt is presented as a result of a call to halt_IO() |
|
A pending status was found. The I/O request (if any) was not initiated. This status might have been presented delayed, after do_IO() or halt_IO() have successfully be started previously. |
|
This is a final interrupt status for the I/O request identified by intparm. |
If device status DEVSTAT_FLAG_SENSE_AVAIL is indicated in field dev_id->flag, field dev_id->scnt describes the number of device specific sense bytes available in the sense area dev_id->ii.sense. No device sensing by the device driver itself is required.
typedef struct {
unsigned char res[32]; /* reserved */
unsigned char data[32]; /* sense data */
} sense_t;
The device interrupt handler can use the following definitions to investigate the primary unit check source coded in sense byte 0:
|
|
0x80 |
|
0x40 |
|
0x20 |
|
0x10 |
|
0x08 |
|
0x04 |
Depending on the device status, multiple of those values may be set together. Please refer to the device specific documentation for details.
The devi_id->cstat field provides the (accumulated) subchannel status:
|
|
Program controlled interrupt |
|
Incorrect length |
|
Program check |
|
Protection check |
|
Channel data check |
|
Channel control check |
|
Interface control check |
|
Chaining check |
The dev_id->dstat field provides the (accumulated) device status:
|
|
Attention |
|
Status modifier |
|
Control unit end |
|
Busy |
|
Channel end |
|
Device end |
|
Unit check |
|
Unit exception |
Please see the ESA/390 Principles of Operation manual for details on the individual flag meanings.
In rare error situations the device driver may require access to the original hardware interrupt data beyond the scope of previously mentioned information. For those situations the Linux/390 common device support provides the interrupt response block (IRB) as part of the device status block in
dev_id->ii.irb.
Prior to call
do_IO() the device driver must assure disabled state, that is, the I/O mask value in the PSW must be disabled. This can be accomplished by calling __save_flags(flags). The current PSW flags are preserved and can be restored by __restore_flags(flags) at a later time.
If the device driver violates this rule while running in a uni-processor environment an interrupt might be presented prior to the
do_IO() routine returning to the device driver main path. In this case we will end in a deadlock situation, as the interrupt handler will try to obtain the IRQ lock the device driver still owns.
The driver must assure to hold the device specific lock. This can be accomplished by
Option (i) should be used if the calling routine is running disabled for I/O interrupts already. Option (ii) obtains the device gate and puts the CPU into I/O disabled state by preserving the current PSW flags.
See the descriptions of s390irq_spin_lock() or s390irq_spin_lock_irqsave() for more details.
The device driver is allowed to issue the next
do_IO() call from within its interrupt handler already. It is not required to schedule a bottom-half, unless an non deterministically long running error recovery procedure or similar needs to be scheduled. During I/O processing the Linux/390 generic I/O device driver support has already obtained the IRQ lock, that is, the handler must not try to obtain it again when calling do_IO() or we end in a deadlock situation. Anyway, the device driver's interrupt handler must only call do_IO() if the handler itself can be entered recursively if do_IO(), for example, it finds a status pending and needs to all the interrupt handler itself.
Device drivers should not rely on
DOIO_WAIT_FOR_INTERRUPT synchronous I/O request processing too heavily. All I/O devices, but the console device are driven using a single shared interrupt subclass (ISC). For synchronous processing the device is temporarily mapped to a special ISC while the calling CPU waits for I/O completion. As this special ISC is gated, all synchronous requests in an SMP environment are serialized which may cause other CPUs to spin. This service is primarily meant to be used during device driver initialization for ease of device setup.
The lpm input parameter might be used for multi-path devices shared among multiple systems as the Linux/390 CDS is not grouping channel paths. Therefore, its use might be required if multiple access paths to a device are available and the device was reserved by means of a reserve device command (for devices supporting this technique). When issuing this command the device driver needs to extract the
dev_id->lpum value and restrict all subsequent channel programs to this channel path until the device is released by a device release command. Otherwise a deadlock may occur.
If a device driver relies on an I/O request to be completed prior to start the next it can reduce I/O processing overhead by chaining a no-op I/O command
CCW_CMD_NOOP to the end of the submitted CCW chain. This will force Channel-End and Device-End status to be presented together, with a single interrupt.
However, this should be used with care as it implies the channel will remain busy, not being able to process I/O requests for other devices on the same channel. Therefore, for example, read commands should never use this technique, as the result will be presented by a single interrupt anyway.
In order to minimize I/O overhead, a device driver should use the
DOIO_REPORT_ALL only if the device can report intermediate interrupt information prior to device-end the device driver urgently relies on. In this case all I/O interruptions are presented to the device driver until final status is recognized.
If a device is able to recover from asynchronously presented I/O errors, it can perform overlapping I/O using the
DOIO_EARLY_NOTIFICATION flag. While some devices always report channel-end and device-end together, with a single interrupt, others present primary status (channel-end) when the channel is ready for the next I/O request and secondary status (device-end) when the data transmission has been completed at the device.
The previously mentioned flag allows exploitation of this feature, for example, for communication devices that can handle lost data on the network to allow for enhanced I/O processing.
Unless the channel subsystem at any time presents a secondary status interrupt, exploiting this feature will cause only primary status interrupts to be presented to the device driver while overlapping I/O is performed. When a secondary status without error (alert status) is presented, this indicates successful completion for all overlapping
do_IO() requests that have been issued since the last secondary (final) status.
During interrupt processing the device specific interrupt handler should avoid basing its processing decisions on the interruption response block (IRB) that is part of the dev_id buffer area. The IRB area represents the interruption parameters from the last interrupt received. Unless the device driver has specified
DOIO_REPORT_ALL or is called with a pending status (DEVSTAT_STATUS_PENDING), the IRB information may or may not show the complete interruption status, but the last interrupt only. Therefore the device driver should usually base its processing decisions on the values of dev_id->cstat and dev_id->dstat that represent the accumulated subchannel and device status information gathered since do_IO() request initiation.
Sometimes a device driver might need a possibility to stop the processing of a long-running channel program or the device might require to initially issue a halt subchannel (HSCH) I/O command. For those purposes the
halt_IO() command is provided.
int halt_IO( int IRQ, /* subchannel number */ int intparm, /* dummy intparm */ unsigned int flag); /* operation mode */
|
|
IRQ (subchannel) the halt operation is requested for |
|
Interruption parameter; value is only used if no I/O is outstanding, otherwise the intparm associated with the I/O request is returned |
|
0 (zero) or DOIO_WAIT_FOR_INTERRUPT |
The
halt_IO() function returns:
|
|
Successful completion or request successfully initiated |
|
The device is currently performing a synchronous I/O operation: do_IO() with flag DOIO_WAIT_FOR_INTERRUPT or an error was encountered and the device is currently be sensed |
|
The IRQ specified does not specify a valid subchannel, the device is not operational (check dev_id.flags) or the IRQ is not owned. |
A device driver may write a never-ending channel program by writing a channel program that at its end loops back to its beginning by means of a transfer in channel (TIC) command (CCW_CMD_TIC). Usually network device drivers perform this by setting the PCI CCW flag (CCW_FLAG_PCI). Once this CCW is executed a program controlled interrupt (PCI) is generated. The device driver can then perform an appropriate action. Prior to interrupt of an outstanding read to a network device (with or without PCI flag) a
halt_IO() is required to end the pending operation.
We do not allow the stopping of synchronous I/O requests by means of a
halt_IO() call. The function will return -EBUSY instead.
This section describes various routines to be used in a Linux/390 device driver programming environment.
s390irq_spin_lock() / s390irq_spin_unlock()
These two macro definitions are required to obtain the device specific IRQ lock. The lock needs to be obtained if the device driver intends to call
do_IO() or halt_IO() from anywhere but the device interrupt handler (where the lock is already owned). Those routines must only be used if running disabled for interrupts already. Otherwise use s390irq_spin_lock_irqsave() and the corresponding unlock routine instead.
s390irq_spin_lock( int IRQ); s390irq_spin_unlock( int IRQ);
s390irq_spin_lock_irqsave() / s390_IRQ_spin_unlock_irqrestore()
These two macro definitions are required to obtain the device specific IRQ lock. The lock needs to be obtained if the device driver intends to call do_IO() or halt_IO() from anywhere but the device interrupt handler (where the lock is already owned). Those routines should only be used if running enabled for interrupts. If running disabled already, the driver should use s390irq_spin_lock() and the corresponding unlock routine instead.
s390irq_spin_lock_irqsave( int IRQ, unsigned long flags); s390irq_spin_unlock_irqrestore( int IRQ, unsigned long flags);
This section describes the special interface routines required for system console processing. Though they are an extension to the Linux/390 device driver interface concept, they base on the same principles. It was necessary to build those extensions to assure a deterministic behavior in critical situations, for example,
printk() messages by other device drivers running disabled for interrupts during I/O interrupt handling or in case of a panic() message being raised.
This routine allows specification of the system console device. This is necessary as the console is not driven by the same ESA/390 interrupt subclass as are other devices, but it is assigned its own interrupt subclass. Only one device can act as system console. See
wait_cons_dev() for details.
int set_cons_dev( int IRQ);
|
IRQ |
Subchannel identifying the system console device |
The
set_cons_dev() function returns
|
|
Successful completion |
|
An unhandled interrupt condition is pending for the specified subchannel (IRQ) - status pending |
|
IRQ does not specify a valid subchannel or the device is not operational |
|
The console device is already defined |
This routine allows for resetting the console device specification. See "2.12.1 set_cons_dev() - Set Console Device" on page
* for details.int reset_cons_dev( int IRQ);
|
IRQ |
Subchannel identifying the system console device |
The
reset_cons_dev() function returns
|
|
Successful completion |
|
An unhandled interrupt condition is pending for the specified subchannel (IRQ) - status pending |
|
IRQ does not specify a valid subchannel or the device is not operational |
The
wait_cons_dev() routine is used by the console device driver when its buffer pool for intermediate request queuing is exhausted and a new output request is received. In this case the console driver uses the wait_cons_dev() routine to synchronously wait until enough buffer space is gained to enqueue the current request. Any pending interrupt condition for the console device found during wait_cons_dev() processing causes its interrupt handler to be called.
int wait_cons_dev( int IRQ);
|
IRQ |
Subchannel identifying the system console device |
The wait_cons_dev() function returns :
|
|
Successful completion |
|
The IRQ specified does not match the IRQ configured for the console device by set_cons_dev() |
The function should be used carefully. Especially in a SMP environment the
wait_cons_dev() processing requires that all but the special console ISC are disabled. In a SMP system this requires the other CPUs to be signaled to disable/enable those ISCs.
Linux/390 uses the following major and minor device numbers.
0 = /dev/dasd0 First DASD device, major 1 = /dev/dasd0a First DASD device, block 1 2 = /dev/dasd0b First DASD device, block 2 3 = /dev/dasd0c First DASD device, block 3 4 = /dev/dasd1 Second DASD device, major 5 = /dev/dasd1a Second DASD device, block 1 6 = /dev/dasd1b Second DASD device, block 2 7 = /dev/dasd1c Second DASD device, block 3
0 = /dev/mnd0 First VM/ESA minidisk 1 = /dev/mnd1 Second VM/ESA minidisk
![]()
The following section was copied from the
Documentation/390 directory of the Linux distribution. It was written by Indo Adlung and is copyright IBM 1999, under the GNU Public License.
Linux manages S/390_s disk devices (DASD) via the DASD device driver. It is valid for all types of DASDs and represents them to Linux as block devices, namely "DASD". Currently the DASD driver uses a single major number (94) and 4 minor numbers per volume (1 for the physical volume and 3 for partitions). With respect to partitions see the following discussion. Thus you may have up to 64 DASD devices in your system.
The kernel parameter 'dasd=from-to,...' may be issued arbitrary times in the kernel's parameter line or not at all. The 'from' and 'to' parameters are to be given in hexadecimal notation without a leading 0x.
If you supply kernel parameters the different instances are processed in order of appearance and a minor number is reserved for any device covered by the supplied range up to 64 volumes. Additional DASDs are ignored. If you do not supply the 'dasd=' kernel parameter at all, the DASD driver registers all supported DASDs of your system to a minor number in ascending order of the subchannel number.
The driver currently supports ECKD-devices and there are stubs for support of the FBA and CKD architectures. For the FBA architecture only some smart data structures are missing to make the support complete.
We performed our testing on 3380 and 3390 type disks of different sizes, under VM and on the bare hardware (LPAR), using internal disks of the Multiprise as well as a RAMAC virtual array. Disks exported by an Enterprise Storage Server (Seascape) should work fine as well.
We currently implement one partition per volume, which is the whole volume, skipping the first blocks up to the volume label. These are reserved for IPL records and IBM's volume label to assure accessibility of the DASD from other operating systems. In a later stage we will provide support of partitions, maybe VTOC oriented or using a kind of partition table in the label record.
For using an ECKD-DASD as a Linux hard disk you have to low-level format the tracks by issuing the
BLKDASDFORMAT-ioctl on that device. This will erase any data on that volume including IBM volume labels, VTOCs etceteras. The ioctl may take a 'struct format_data *' or 'NULL' as an argument.
typedef struct {
int start_unit;
int stop_unit;
int blksize;
} format_data_t;
When a NULL argument is passed to the
BLKDASDFORMAT ioctl the whole disk is formatted to a blocksize of 1024 bytes. Otherwise start_unit and stop_unit are the first and last track to be formatted. If stop_unit is -1 it implies that the DASD is formatted from start_unit up to the last track. blksize can be any power of two between 512 and 4096. We recommend no blksize lower than 1024 because the ext2fs uses 1kB blocks anyway and you gain approximately 50% of capacity increasing your blksize from 512 byte to 1kB.
Then you can mk??fs the filesystem of your choice on that volume or partition. For reasons of sanity you should build your filesystem on the partition
/dev/dd?1 instead of the whole volume. You only lose 3kB but may be sure that you can reuse your data after introduction of a real partition table.
![]()
The following is a list of files, and their functions, which were added to the Linux distribution by the Linux/390 developers.
|
File |
Description |
|
Perform low level format of DASD |
|
Code to support IPL from ECKD device |
|
Code to support IPL from FBA device |
|
S/390 support of SILO |
|
Various bitmaps used by test/set functions |
|
Issue CP command from Linux (DIAG 8) |
|
Header file for CP command support |
|
EBCDIC/ASCII translation tables and conversion routines |
|
S/390 Low-level entry points |
|
LIBGCC for software floating point |
|
Enable debugger support within kernel |
|
Routine to handle boot and kernel setup |
|
Header file for IEEE floating point support |
|
Initial task structure |
|
S/390 IRQ instantiation |
|
Header file for IRQ support |
|
Channel support code |
|
Mapping of S/390 low-core areas |
|
Handle IEEE floating point on S/390 |
|
Handle the S/390-dependent parts of process handling |
|
Kernel tracing support |
|
Floating point support code |
|
I/O support routines (such as read device chars/DIAG 210) |
|
Header file for S/390 I/O support routines |
|
Kernel symbols |
|
Handles the architecture-dependent parts of initialization |
|
Signal handling (not SIGP but software signals) |
|
SMP support (the SIGP stuff) |
|
Handle system calls that use non-standard call sequences |
|
Time support routines (for example, gettimeofday()) |
|
Handles hardware traps and faults after initial save |
|
Network checksum routines (uses CKSM instruction) |
|
Delay routines |
|
Fast memset routine (uses MVCLE) |
|
Fast strcmp routine (uses CLST) |
|
Fast strncpy routine |
|
Page fault exception table processing |
|
Page fault handling |
|
Memory initialization routines |
|
Re-map IO memory to kernel address space |
|
Header that maps the a.out object format |
|
Atomic operations that C cannot guarantee |
|
Various bit-operation macros and definitions |
|
Included by main.c to check for S/390-dependent bugs |
|
Various byte ordering/reordering routines |
|
Level 1 cache definitions |
|
Fast network checksum routines |
|
S/390 definition of the "current" variable |
|
Delay routine header file |
|
DMA header file (dummy I guess) |
|
EBCDIC/ASCII translate table & routine header file |
|
ELF-390 definitions |
|
Error number definitions |
|
File control routine, structure, and variable definitions |
|
Debugger stub support definitions |
|
I/O interrupt definitions, structures and variables |
|
init.c support definitions |
|
Low-level I/O support definitions |
|
IOCTL command support definitions |
|
IOCTL related definitions |
|
Inter-Process Communication definitions |
|
Interrupt routine definitions |
|
Channel related definitions |
|
Map of low core |
|
IEEE floating point emulation support definitions |
|
Machine-specific definitions |
|
Miscellaneous alignment definitions |
|
Memory Map ( mmap()) related definitions |
|
Memory management context definitions |
|
Support definitions for namei() |
|
Page and paging related definitions |
|
System parameters |
|
Page table definitions (3 tier + 2 tier model mapping) |
|
|
|
POSIX type definitions |
|
CPU type and hardware definitions |
|
Processor trace related definitions |
|
Queuing related definitions |
|
|
|
S/390-dependent debugging definitions |
|
Designed to keep compatibility between gdb's & the kernels representation of registers |
|
Code/Data segment definitions (dummy for S/390) |
|
Additional semaphore support definitions |
|
Semaphore routine support definitions |
|
Initial system setup support definitions |
|
Shared memory parameter definitions |
|
Signal context definitions |
|
Signal information definitions |
|
Signal routine support definitions |
|
Signal processor (SIGP) support definitions |
|
SMP routine support definitions |
|
SMP locking routine support definitions |
|
Socket routine support definitions |
|
Socket IOCTL related definitions |
|
|
|
Interrupt routine support definitions |
|
Spin/read/write lock routine support definitions |
|
|
|
String routine support definitions (e.g. memchr()) |
|
System routine support definitions (e.g. cli(), sti()) |
|
Additional termios related definitions |
|
Terminal I/O routine support definitions |
|
Clock cycle related definitions |
|
C types used by Linux/390 |
|
User space memory access support definitions |
|
User context definitions |
|
Unaligned memory access definitions |
|
Standard UNIX definitions |
|
Core file layout definitions |
|
DASD I/O routines |
|
DASD I/O routine support definitions |
|
DASD I/O CCW related processing ([en|de]queuing) |
|
DASD I/O CCW support definitions |
|
ECKD I/O routines |
|
|
|
DASD profiling |
|
DASD type definitions (ECKD, CKD, FBA) |
|
VM minidisk I/O routines |
|
VM minidisk I/O routine support definitions |
|
3215 line-mode console I/O routines |
|
Hardware console I/O routine support definitions |
|
Hardware line-mode console I/O routines |
|
Reading/writing from/to system console via HWC |
|
HWC read/write support definitions |
|
HWC line-mode console driver |
|
EBCDIC/ASCII tables and conversion routines |
|
CTCA network driver |
|
IUCV network driver |
|
IUCV network driver support definitions |
![]()
The Linux/390 system calls are implemented via SVC. Each call corresponds to a different SVC.
|
# |
Function |
# |
Function |
|
1 |
|
97 |
|
|
2 |
|
99 |
|
|
3 |
|
100 |
|
|
4 |
|
101 |
|
|
5 |
|
102 |
|
|
6 |
|
103 |
|
|
7 |
|
104 |
|
|
8 |
|
105 |
|
|
9 |
|
106 |
|
|
10 |
|
107 |
|
|
11 |
|
108 |
|
|
12 |
|
109 |
|
|
13 |
|
111 |
|
|
14 |
|
112 |
|
|
15 |
|
114 |
|
|
16 |
|
115 |
|
|
18 |
|
116 |
|
|
19 |
|
117 |
|
|
20 |
|
118 |
|
|
21 |
|
119 |
|
|
22 |
|
120 |
|
|
23 |
|
121 |
|
|
24 |
|
122 |
|
|
25 |
|
124 |
|
|
26 |
|
125 |
|
|
27 |
|
126 |
|
|
28 |
|
127 |
|
|
29 |
|
128 |
|
|
30 |
|
129 |
|
|
33 |
|
130 |
|
|
34 |
|
131 |
|
|
36 |
|
132 |
|
|
37 |
|
133 |
|
|
38 |
|
134 |
|
|
39 |
|
135 |
|
|
40 |
|
136 |
|
|
41 |
|
138 |
|
|
42 |
|
139 |
|
|
43 |
|
140 |
|
|
45 |
|
141 |
|
|
46 |
|
142 |
|
|
47 |
|
143 |
|
|
48 |
|
144 |
|
|
49 |
|
145 |
|
|
50 |
|
146 |
|
|
51 |
|
147 |
|
|
54 |
|
148 |
|
|
55 |
|
149 |
|
|
57 |
|
150 |
|
|
59 |
|
151 |
|
|
60 |
|
152 |
|
|
61 |
|
153 |
|
|
62 |
|
154 |
|
|
63 |
|
155 |
|
|
64 |
|
156 |
|
|
65 |
|
157 |
|
|
66 |
|
158 |
|
|
67 |
|
159 |
|
|
68 |
|
160 |
|
|
69 |
|
161 |
|
|
70 |
|
162 |
|
|
71 |
|
163 |
|
|
72 |
|
164 |
|
|
73 |
|
165 |
|
|
74 |
|
167 |
|
|
75 |
|
168 |
|
|
76 |
|
169 |
|
|
77 |
|
170 |
|
|
78 |
|
171 |
|
|
79 |
|
172 |
|
|
80 |
|
173 |
|
|
81 |
|
174 |
|
|
82 |
|
175 |
|
|
83 |
|
176 |
|
|
84 |
|
177 |
|
|
85 |
|
178 |
|
|
86 |
|
179 |
|
|
87 |
|
180 |
|
|
88 |
|
181 |
|
|
89 |
|
182 |
|
|
90 |
|
183 |
|
|
91 |
|
184 |
|
|
92 |
|
185 |
|
|
93 |
|
186 |
|
|
94 |
|
187 |
|
|
95 |
|
190 |
|
|
96 |
|
255 |
|
![]()
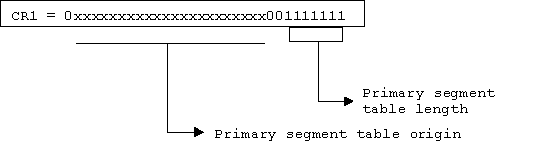
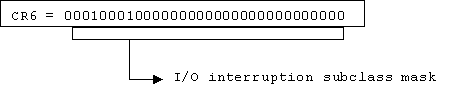
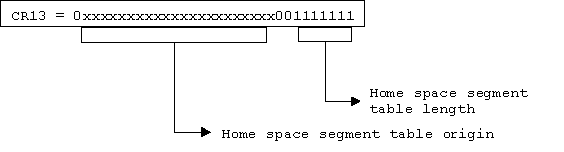
Linux/390 uses the following control register settings.
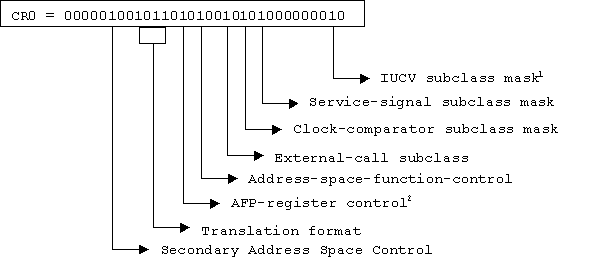
Notes:
These registers are used for linkage-stack and address space operations. The registers are saved and restored for each task but never set.

This register is used for Monitor Calls (MC). The register is saved and restored for each task but never set.
These registers are used for Program Event Recording (PER). The registers saved and restored for each task but never set.
This register is used for tracing. The register is saved and restored for each task but never set.

This register is used for linkage-stack operations. The register is saved and restored for each task but never set.
![]()
Control Register 7 (secondary space control) and Control Register 13 (Home space control) are set to the user pgdir. The Kernel is running in its own, disjunct address space, and running in primary address space. A "Copy to/from user" is done via access register mode with access registers (AR2 and AR4) set to 0 or 1. For that purpose we need set up CR 7 with the user pgd.
![]()
The following section illustrates the IPL process from the VM reader.
When you first download the kernel image you will need to load it, the boot parameters and the RAMDISK from the VM reader. The RAMDISK contains just enough of a normal filesystem to complete the boot process. It will allow you to mount and configure "real" filesystems which can then take over as the root filesystem.

The initial boot parameters are as follows:

These parameters have the following meaning:
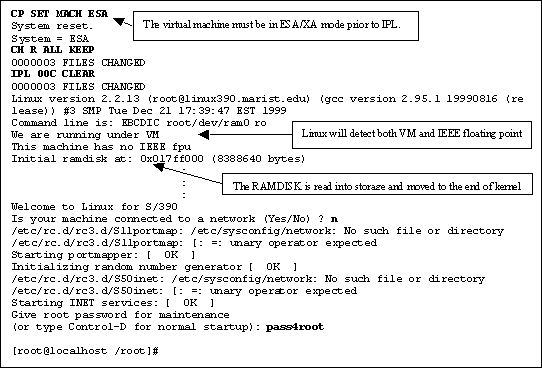
When Linux has a "real" root filesystem and booted, it requires only the kernel code and parameters to reside in the VM reader.

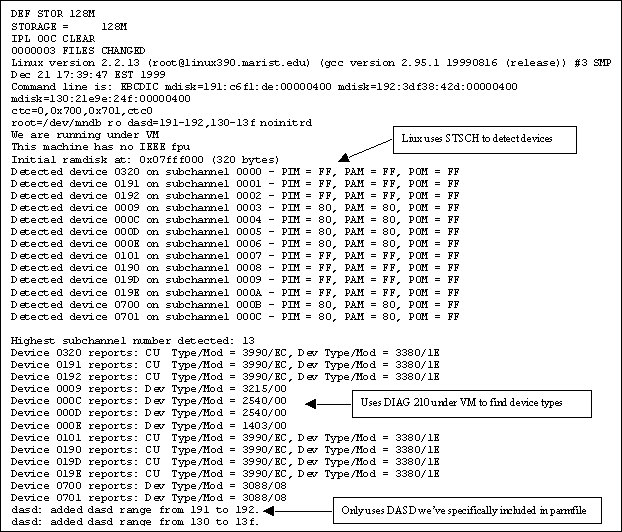
The parameters for this boot are more complex. They describe VM minidisks, CTC devices, the location of the root file system and the DASD to be included.

For a "full-functioned" Linux system IBM recommend a 128MB virtual machine:

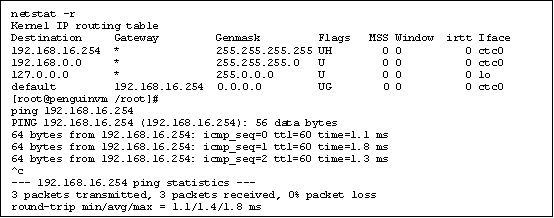
As part of the boot process the network is brought online. The following netstat display shows the routing table for the system:
The network definitions responsible for the network activation are found in /etc/sysconfig/network:

And in /etc/sysconfig/network-scripts/ifcfg-ctc0:

With the network in place, it is now possible to telnet into the Linux/390 system and discard working from the emulated 3215 session:

Following an initial load of Linux/390 you will need to install either the "small" file system (120MB) or the "large" file system (400MB). If you have no access to TCP/IP you will be unable to FTP or NFS mount the files. You can copy a file system from one Linux system to another using a loopback device.
There are a number of steps to this, but they can be described as follows.
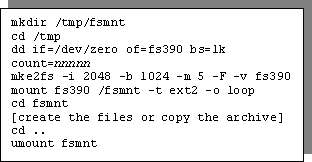
by
Denis Joseph Barrow (djbarrow@de.ibm.com, barrow_dj@yahoo.com)
Copyright (C) 2000 IBM Deutschland Entwicklung GmbH, IBM Corporation
This document is intended to give an good overview of how to debug Linux for S390 it isn't intended as a complete reference and not a tutorial on the fundamentals of C and assembly, it doesn't go into 390 IO in any detail. It is intended to compliment the following books.
It is intended like the Enterprise Systems Architecture/390 Reference Summary to be printed out and used as a quick cheat sheet self help style reference when problems occur.
The Linux for S390 Kernel Task Structure
Register Usage and Stackframes on Linux for S390 with glossary
Compiling programs for debugging on Linux for S390
Starting points for debugging scripting languages etc.
The current ESA 390 architecture has the following registers.
Note: Linux (currently) always uses IEEE and emulates G5 IEEE format on older machines, (provided the kernel is configured for this ).
The PSW is the most important register on the machine it is 64 bit and serves the roles of a program counter (PC), condition code register, memory space designator.
In IBM standard notation I am counting bit 0 as the MSB. It has several advantages over a normal program counter in that you can change address translation and program counter in a single instruction. To change address translation, e.g. switching address translation off requires that you have a logical=physical mapping for the address you are currently running at.
|
Bit |
Value |
|
0 |
Reserved (must be 0 otherwise specification exception occurs) |
|
1 |
Program Event Recording 1 PER enable. PER is used to facilititate debugging e.g. single stepping. |
|
2-4 |
Reserved (must be 0). |
|
5 |
Dynamic address translation 1=DAT on. |
|
6 |
Input/Output interrupt Mask |
|
7 |
External interrupt Mask used primarily for interprocessor signalling and clock interrupts. |
|
8-12 |
PSW Key used for complex memory protection mechanism not used under Linux |
|
13 |
Machine Check Mask 1=enable machine check interrupts |
|
14 |
Wait State set this to 1 to stop the processor except for interrupts and give time to other LPARS used in CPU idle in the kernel to increase overall usage of processor resources. |
|
15 |
Problem state (if set to 1 certain instructions are disabled) all Linux user programs run with this bit 1 (useful info for debugging under VM). |
|
16-17 |
Address Space Control 00 Primary Space Mode when DAT on. The Linux kernel currently runs in this mode: CR1 is affiliated with this mode and points to the primary segment table origin etc.
|
|
18-19 |
Condition codes (CC) |
|
20 |
Fixed point overflow mask if 1=FPU exceptions for this event occur(normally 0) |
|
21 |
Decimal overflow mask if 1=FPU exceptions for this event occur (normally0) |
|
22 |
Exponent underflow mask if 1=FPU exceptions for this event occur(normally 0) |
|
23 |
Significance Mask if 1=FPU exceptions for this event occur ( normally0 ) |
|
24-31 |
Reserved Must be 0. |
|
32 |
1=31 bit addressing mode 0=24 bit addressing mode (for backwardcompatibility ). Linux always runs with this bit set to 1 |
|
33-64 |
Instruction address. |
This per CPU memory area is too intimately tied to the processor not to mention. It exists between the real addresses 0-4096 on the processor and is exchanged with a page in absolute storage by the set prefix instruction in Linux's startup. This page different on each processor. Bytes 0-512 (200 hex) are used by the processor itself for holding such information as exception indications and entry points for exceptions.
Linux uses bytes after 0xc00 hex for per processor globals. The closest thing to this on traditional architectures is the interrupt vector table. This is a good thing and does simplify some of the kernel coding however it means that we now cannot catch stray NULL pointers in the kernel without hard coded checks.
The traditional Intel Linux is approximately mapped as follows:
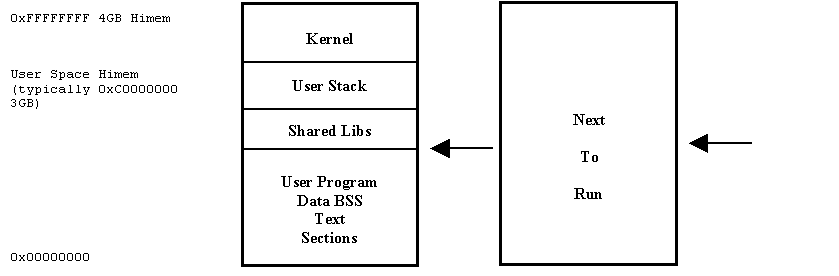
Now it is easy to see that on Intel it is quite easy to recognize a kernel address as being one greater than user space high memory (in this case 0xC0000000). Addresses of less than this are the ones in the current running program on this processor (if an SMP box). If using the virtual machine (VM) as a debugger it is quite difficult to know which user process is running as the address space you are looking at could be from any process in the run queue. Thankfully you normally get lucky as address spaces don't overlap that and you can recognize the code at by cross-referencing with a dump made by objdump (more about that later).
The limitation of Intels addressing technique is that the Linux kernel uses a very simple real address to virtual addressing technique of Real Address=Virtual Address-User Space Himem. This means that on Intel the kernel Linux can typically only address Himem=0xFFFFFFFF-0xC0000000=1GB and this is all the RAM these machines can typically use. They can lower User Himem to 2GB or lower and thus be able to use 2GB of RAM however this shrinks the maximum size of User Space from 3GB to 2GB they have a no win limit of 4GB unless they go to 64 Bit.
On S/390 our limitations and strengths make us slightly different. For backward compatibility we are only allowed use 31 bits (2GB) of our 32 bit addresses, however, we use entirely separate address spaces for the user and kernel. This means we can support 2GB of non-extended RAM, and more with the extended memory management swap device and 64 Bit when it comes along.
Our addressing scheme is as follows:

This also means that we need to look at the PSW problem state bit or the addressing mode to decide whether we are looking at user or kernel space.
Each process/thread under Linux for S390 has its own kernel task_struct defined in linux/include/linux/sched.h. The S390 on initialisation and resuming of a process on a cpu sets the __LC_KERNEL_STACK variable in the spare prefix area for this cpu (which we use for per processor globals). The kernel stack pointer is intimately tied with the task structure for each processor as follows.
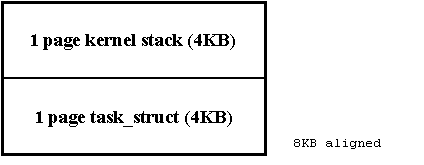
What this means is that we don't need to dedicate any register or global variable to point to the current running process and can retrieve it with the following very simple construct:
static inline struct task_struct * get_current(void)
{
struct task_struct *current;
__asm__("lhi %0,-8192\n\t"
"nr %0,15"
: "=r" (current) );
return current;
}
That is, just and'ing the current kernel stack pointer with the mask -8192. Thankfully because Linux doesn't have support for nested IO interrupts and our devices have large buffers can survive interrupts being shut for short amounts of time we don't need a separate stack for interrupts.
This is the code that gcc produces at the top and the bottom of each function. It usually is fairly consistent and similar from function to function and if you know its layout you can probably make some headway in finding the ultimate cause of a problem after a crash without a source level debugger.
Note: To follow stackframes requires knowledge of C or Pascal and limited knowledge of one assembly language.
|
alloca |
This is a built in compiler function for runtime allocation of extra space on the caller's stack that is obviously freed up on function exit. For example, the caller may choose to allocate nothing of a buffer of 4k if required for temporary purposes. It generates very efficient code (a few cycles) when compared to alternatives like malloc. |
|
automatics |
These are local variables on the stack, that is, they aren't in registers and they aren't static. |
|
back-chain |
This is a pointer to the stack pointer before entering a framed functions (see frameless function) prologue got by de-referencing the address of the current stack pointer, i.e. got by accessing the 32 bit value at the stack pointers current location. |
|
base-pointer |
This is a pointer to the back of the literal pool which is an area just behind each procedure used to store constants in each function. |
|
call-clobbered |
The caller probably needs to save these registers if there is something of value in them, on the stack or elsewhere before making a call to another procedure so that it can restore it later. |
|
epilogue |
The code generated by the compiler to return to the caller. |
|
frameless-function |
A frameless function in Linux for 390 is one that doesn't need more than the 96 bytes given to it by the caller. A frameless function never:
|
|
GOT-pointer |
This is a pointer to the global-offset-table in ELF (Executable Linkable Format, Linux's most common executable format). All globals and shared library objects are found using this pointer. |
|
lazy-binding |
ELF shared libraries are typically only loaded when routines in the shared library are actually first called at runtime. |
|
procedure-linkage-table |
This is a table found from the GOT which contains pointers to routines in other shared libraries which can't be called to by easier means. |
|
prologue |
The code generated by the compiler to set up the stack frame. |
|
outgoing-args |
This is extra area allocated on the stack of the calling function if the parameters for the callee's cannot all be put in registers, the same area can be reused by each function the caller calls. |
|
routine-descriptor |
A COFF executable format based concept of a procedure reference actually being 8 bytes or more as opposed to a simple pointer to the routine. This is typically defined as follows:
|
|
static-chain |
This is used in nested functions a concept adopted from pascal by gcc not used in ansi C or C++ (although quite useful), basically it is a pointer used to reference local variables of enclosing functions. You might come across this stuff once or twice in your lifetime. For example, the function below should return 11 though gcc may get upset and toss warnings about unused variables. int FunctionA(int a)
{
int b;
FunctionC(int c)
{
b=c+1;
}
FunctionC(10);
return(b);
} |
|
r0 |
used by syscalls/assembly |
call-clobbered |
|
r1 |
used by syscalls/assembly |
call-clobbered |
|
r2 |
argument 0 / return value 0 |
call-clobbered |
|
r3 |
argument 1 / return value 1 (if long long) |
call-clobbered |
|
r4 |
argument 2 |
call-clobbered |
|
r5 |
argument 3 |
call-clobbered |
|
r6 |
argument 5 |
saved |
|
r7 |
pointer-to arguments 5 to ... |
saved |
|
r8 |
this and that |
saved |
|
r9 |
this and that |
saved |
|
r10 |
static-chain ( if nested function ) |
saved |
|
r11 |
frame-pointer (if function used alloca) |
saved |
|
r12 |
got-pointer |
saved |
|
r13 |
base-pointer |
saved |
|
r14 |
return-address |
saved |
|
r15 |
stack-pointer |
saved |
|
f0 |
argument 0 / return value ( float/double ) |
call-clobbered |
|
f2 |
argument 1 |
call-clobbered |
|
f4 |
saved |
|
|
f6 |
saved |
|
|
The remaining floating points f1,f3,f5 f7-f15 are call-clobbered. |
||
Notes:
|
0 |
back chain (a 0 here signifies end of back chain) |
|
4 |
eos (end of stack, not used on Linux for S390 used in other linkage formats) |
|
8 |
glue used in other linkage formats for saved routine descriptors etc. |
|
12 |
glue used in other linkage formats for saved routine descriptors etc. |
|
16 |
scratch area |
|
20 |
scratch area |
|
24 |
saved r6 of caller function |
|
28 |
saved r7 of caller function |
|
32 |
saved r8 of caller function |
|
36 |
saved r9 of caller function |
|
40 |
saved r10 of caller function |
|
44 |
saved r11 of caller function |
|
48 |
saved r12 of caller function |
|
52 |
saved r13 of caller function |
|
56 |
saved r14 of caller function |
|
60 |
saved r15 of caller function |
|
64 |
saved f4 of caller function |
|
72 |
saved f6 of caller function |
|
80 |
undefined |
|
96 |
outgoing args passed from caller to callee |
|
96+x |
possible stack alignment (8 bytes desirable) |
|
96+x+y |
alloca space of caller (if used) |
|
96+x+y+z |
automatics of caller (if used) |
|
0 |
back-chain |
0040037c int test(int b)
{ # Function prologue below
40037c: 90 de f0 34 stm %r13,%r14,52(%r15) # Save registers r13 & r14
400380: 0d d0 basr %r13,%r0 # Set up pointer to constant pool using
400382: a7 da ff fa ahi %r13,-6 # basr trick
return(5+b);
# Huge main program
400386: a7 2a 00 05 ahi %r2,5 # add 5 to r2
# Function epilogue below
40038a: 98 de f0 34 lm %r13,%r14,52(%r15) # restore registers r13 & 14
40038e: 07 fe br %r14 # return
} The compiler did this function optimally ( 8-) )
Literal pool for main.
400390: ff ff ff ec .long 0xffffffec
main(int argc,char *argv[])
{ # Function prologue below
400394: 90 bf f0 2c stm %r11,%r15,44(%r15) # Save necessary registers
400398: 18 0f lr %r0,%r15 # copy stack pointer to r0
40039a: a7 fa ff a0 ahi %r15,-96 # Make area for callee saving
40039e: 0d d0 basr %r13,%r0 # Set up r13 to point to
4003a0: a7 da ff f0 ahi %r13,-16 # literal pool
4003a4: 50 00 f0 00 st %r0,0(%r15) # Save backchain
return(test(5)); # Main Program Below
4003a8: 58 e0 d0 00 l %r14,0(%r13) # load relative address of test from
# literal pool
4003ac: a7 28 00 05 lhi %r2,5 # Set first parameter to 5
4003b0: 4d ee d0 00 bas %r14,0(%r14,%r13) # jump to test setting r14 as return
# address using branch & save instruction.
# Function Epilogue below
4003b4: 98 bf f0 8c lm %r11,%r15,140(%r15) # Restore necessary registers.
4003b8: 07 fe br %r14 # return to do program exit
}
Make sure that the gcc is compiling and linking with the -g flag on. This is typically done adding/appending the flags -g to the CFLAGS and LDFLAGS variables Makefile of the program concerned.
If using gdb and you would like accurate displays of registers and stack traces compile without optimization. That is, make sure that there is no -O2 or similar on the CFLAGS line of the Makefile and the emitted gcc commands, obviously this will produce worse code (not advisable for shipment) but it is an aid to the debugging process.
This aids debugging because the compiler will copy parameters passed in in registers onto the stack so backtracing and looking at passed in parameters will work, however some larger programs which use inline functions will not compile without optimisation.
If you are getting a lot of syntax errors compiling a program and the problem isn't blatantly obvious from the source. It often helps to just preprocess the file, this is done with the -E option in gcc. What this does is that it runs through the very first phase of compilation (compilation in gcc is done in several stages and gcc calls many programs to achieve its end result) with the -E option gcc just calls the gcc preprocessor (cpp). The c preprocessor does the following, it joins all the files #included together recursively ( #include files can #include other files ) and also the c file you wish to compile. It puts a fully qualified path of the #included files in a comment and it does macro expansion. This is useful for debugging because
For convenience the Linux kernel's makefile will do preprocessing automatically for you by suffixing the file you want built with .i (instead of .o). For example, from the Linux directory type:
make arch/s390/kernel/signal.i
this will build :
s390-gcc -D__KERNEL__ -I/home1/barrow/linux/include -Wall -Wstrict-prototypes -O2 -fomit-frame-pointer -fno-strict-aliasing -D__SMP__ -pipe -fno-strength-reduce -E arch/s390/kernel/signal.c arch/s390/kernel/signal.i
Now look at signal.i you should see something like:
# 1 "/home1/barrow/linux/include/asm/types.h" 1
typedef unsigned short umode_t; typedef __signed__ char __s8; typedef unsigned char __u8; typedef __signed__ short __s16; typedef unsigned short __u16;
If instead you are getting errors further down. For example, unknown instruction: 2515 "move.l" or better still unknown instruction:2515 "Fixme not implemented yet, call Martin" you are probably are attempting to compile some code meant for another architecture or code that is simply not implemented, with a fixme statement stuck into the inline assembly code so that the author of the file now knows he has work to do. To look at the assembly emitted by gcc just before it is about to call gas (the gnu assembler) use the -S option. Again for your convenience the Linux kernel's Makefile will hold your hand and do all this donkey work for you also by building the file with the .s suffix. For example, from the Linux directory type:
make arch/s390/kernel/signal.s s390-gcc -D__KERNEL__ -I/home1/barrow/linux/include -Wall -Wstrict-prototypes -O2 -fomit-frame-pointer -fno-strict-aliasing -D__SMP__ -pipe -fno-strength-reduce -S arch/s390/kernel/signal.c -o arch/s390/kernel/signal.s
This will output something like, (please note the constant pool and the useful comments in the prologue to give you a hand at interpreting it).
.LC54:
.string "misaligned (__u16 *) in __xchg\n"
.LC57:
.string "misaligned (__u32 *) in __xchg\n"
.L$PG1: # Pool sys_sigsuspend
.LC192:
.long -262401
.LC193:
.long -1
.LC194:
.long schedule-.L$PG1
.LC195:
.long do_signal-.L$PG1
.align 4
.globl sys_sigsuspend
.type sys_sigsuspend,@function
sys_sigsuspend:
# leaf function 0
# automatics 16
# outgoing args 0
# need frame pointer 0
# call alloca 0
# has varargs 0
# incoming args (stack) 0
# function length 168
STM 8,15,32(15)
LR 0,15
AHI 15,-112
BASR 13,0
.L$CO1: AHI 13,.L$PG1-.L$CO1
ST 0,0(15)
LR 8,2
N 5,.LC192-.L$PG1(13) This is a tool with many options the most useful being ( if compiled with -g).
objdump --source <victim program or object file> > <victims debug listing>
The whole kernel can be compiled like this (doing this will make a 17MB kernel and a 200 MB listing ) however you have to strip it before building the image using the strip command to make it a more reasonable size to boot it.
A source/assembly mixed dump of the kernel can be done with the line:
objdump --source vmlinux > vmlinux.lst
Also if the file isn't compiled -g this will output as much debugging information as it can (for example, function names). However, this is very slow as it spends lots of time searching for debugging info, the following self explanatory line should be used instead if the code isn't compiled -g.
objdump --disassemble-all --syms vmlinux > vmlinux.lst
as it is much faster.
As hard drive space is valuable most of us use the following approach.
extern inline void spin_lock(spinlock_t *lp)
{
a0: 18 34 lr %r3,%r4
a2: a7 3a 03 bc ahi %r3,956
__asm__ __volatile(" lhi 1,-1\n"
a6: a7 18 ff ff lhi %r1,-1
aa: 1f 00 slr %r0,%r0
ac: ba 01 30 00 cs %r0,%r1,0(%r3)
b0: a7 44 ff fd jm aa <sys_sigsuspend+0x2e>
saveset = current-blocked;
b4: d2 07 f0 68 mvc 104(8,%r15),972(%r4)
b8: 43 cc
return (set-sig[0] and mask) != 0;
} Q. What is it ?
A. It is a tool for intercepting calls to the kernel and logging them to a file and on the screen.
Q. What use is it ?
A. You can used it to find out what files a particular program opens.
If you wanted to know does ping work but didn't have the source:
strace ping -c 1 127.0.0.1
and then look at the man pages for each of the syscalls below, (In fact this is sometimes easier than looking at some spaghetti source which conditionally compiles for several architectures). Not everything that it throws out needs to make sense immediately.
Just looking quickly you can see that it is making up a RAW socket for the ICMP protocol. Doing an alarm(10) for a 10 second timeout and doing a gettimeofday() call before and after each read to see how long the replies took, and writing some text to stdout so the user has an idea what is going on.
socket(PF_INET, SOCK_RAW, IPPROTO_ICMP) = 3
getuid() = 0
setuid(0) = 0
stat("/usr/share/locale/C/libc.cat", 0xbffff134) = -1 ENOENT (No such file or directory)
stat("/usr/share/locale/libc/C", 0xbffff134) = -1 ENOENT (No such file or directory)
stat("/usr/local/share/locale/C/libc.cat", 0xbffff134) = -1 ENOENT (No such file or directory)
getpid() = 353
setsockopt(3, SOL_SOCKET, SO_BROADCAST, [1], 4) = 0
setsockopt(3, SOL_SOCKET, SO_RCVBUF, [49152], 4) = 0
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(3, 1), ...}) = 0
mmap(0, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x40008000
ioctl(1, TCGETS, {B9600 opost isig icanon echo ...}) = 0
write(1, "PING 127.0.0.1 (127.0.0.1): 56 d"..., 42PING 127.0.0.1 (127.0.0.1): 56 data bytes
) = 42
sigaction(SIGINT, {0x8049ba0, [], SA_RESTART}, {SIG_DFL}) = 0
sigaction(SIGALRM, {0x8049600, [], SA_RESTART}, {SIG_DFL}) = 0
gettimeofday({948904719, 138951}, NULL) = 0
sendto(3, "\10\0D\201a\1\0\0\17#\2178\307\36"..., 64, 0, {sin_family=AF_INET,
sin_port=htons(0), sin_addr=inet_addr("127.0.0.1")}, 16) = 64
sigaction(SIGALRM, {0x8049600, [], SA_RESTART}, {0x8049600, [], SA_RESTART}) = 0
sigaction(SIGALRM, {0x8049ba0, [], SA_RESTART}, {0x8049600, [], SA_RESTART}) = 0
alarm(10) = 0
recvfrom(3, "E\0\0T\0005\0\0@\1|r\177\0\0\1\177"..., 192, 0,
{sin_family=AF_INET, sin_port=htons(50882), sin_addr=inet_addr("127.0.0.1")}, [16]) = 84
gettimeofday({948904719, 160224}, NULL) = 0
recvfrom(3, "E\0\0T\0006\0\0\377\1\275p\177\0"..., 192, 0,
{sin_family=AF_INET, sin_port=htons(50882), sin_addr=inet_addr("127.0.0.1")}, [16]) = 84
gettimeofday({948904719, 166952}, NULL) = 0
write(1, "64 bytes from 127.0.0.1: icmp_se"...,
5764 bytes from 127.0.0.1: icmp_seq=0 ttl=255 time=28.0 ms
strace passwd 2>&1 | grep open
produces the following output
open("/etc/ld.so.cache", O_RDONLY) = 3
open("/opt/kde/lib/libc.so.5", O_RDONLY) = -1 ENOENT (No such file or directory)
open("/lib/libc.so.5", O_RDONLY) = 3
open("/dev", O_RDONLY) = 3
open("/var/run/utmp", O_RDONLY) = 3
open("/etc/passwd", O_RDONLY) = 3
open("/etc/shadow", O_RDONLY) = 3
open("/etc/login.defs", O_RDONLY) = 4
open("/dev/tty", O_RDONLY) = 4
The 2>&1 is done to redirect stderr to stdout and grep is then filtering this input through the pipe for each line containing the string open.
Now we are getting sophisticated: telnetd crashes on and I don't know why
#!/bin/bash /usr/bin/strace -o/t1 -f /usr/sbin/in.telnetd -h
However the file /t1 will get big quite quickly to test it telnet 127.0.0.1. Now look at what files in.telnetd execve'd
413 execve("/usr/sbin/in.telnetd", ["/usr/sbin/in.telnetd", "-h"], [/* 17 vars */]) = 0
414 execve("/bin/login", ["/bin/login", "-h", "localhost", "-p"], [/* 2 vars */]) = 0
Whey it worked!
If the program is not very interactive (i.e. not much keyboard input) and is crashing in one architecture but not in another you can do an strace of both programs under as identical a scenario as you can on both architectures outputting to a file then. do a diff of the two traces using the diff program. i.e.
diff output1 output2
and maybe you'll be able to see where the call paths differed, this is possibly near the cause of the crash.
Look at man pages for strace and the various syscalls e.g. man strace, man alarm, man socket.
Addresses and values in the VM debugger are always hex never decimal. Address ranges are of the format <HexValue1>-<HexValue2> or <HexValue1>.<HexValue2.> e.g. The address range 0x2000 to 0x3000 can be described as 2000-3000 or 2000.1000.
The VM Debugger is case insensitive.
VM's strengths are usually other debuggers weaknesses you can get at any resource no matter how sensitive e.g. memory management resources, change address translation in the PSW. For kernel hacking you will reap dividends if you get good at it.
The VM Debugger displays operators but not operands, probably because some of it was written when memory was expensive and the programmer was probably proud that it fitted into 2k of memory and the programmers didn't want to shock hardcore VM'ers by changing the interface :-). Also, the debugger displays useful information on the same line and the author of the code probably felt that it was a good idea not to go over the 80 columns on the screen.
As some of you are probably in a panic now this isn't as unintuitive as it may seem as the 390 instructions are easy to decode mentally and you can make a good guess at a lot of them as all the operands are nibble (half byte aligned ). If you have an objdump listing also it is quite easy to follow. If you don't have an objdump listing keep a copy of the ESA Reference Summary and look at between pages 2 and 7 or alternatively the ESA principles of operation. e.g. even I can guess that
0001AFF8' LR 180F CC 0
is a ( load register ) lr r0,r15
Also it is very easy to tell the length of a 390 instruction from the 2 most significant bits in the instruction (not that this info is really useful except if you are trying to make sense of a hexdump of code):
|
Bits |
Instruction Length |
|
00 |
2 Bytes |
|
01 |
4 Bytes |
|
10 |
4 Bytes |
|
11 |
6 Bytes |
The debugger also displays other useful info on the same line such as the addresses being operated on destination addresses of branches and condition codes. For example:
00019736' AHI A7DAFF0E CC 1 000198BA' BRC A7840004 -> 000198C2' CC 0 000198CE' STM 900EF068 0FA95E78 CC 2
I suppose I'd better mention this before I start to list the current active traces do
Q TR
there can be a maximum of 255 of these per set (more about trace sets later). To stop traces issue:
TR END
To delete a particular breakpoint issue
TR DEL <breakpoint number>
The PA1 key drops to CP mode so you can issue debugger commands, Doing alt-c (on my 3270 console at least ) clears the screen. Hitting b <enter> comes back to the running operating system from CP mode (in our case Linux ).
It is typically useful to add shortcuts to your PROFILE EXEC file if you have one (this is roughly equivalent to autoexec.bat in DOS or .profile in Linux). Here are a few from mine:
/* this gives me command history on issuing f12 */ set pf12 retrieve /* this continues */ set pf8 imm b /* goes to trace set a */ set pf1 imm tr goto a /* goes to trace set b */ set pf2 imm tr goto b /* goes to trace set c */ set pf3 imm tr goto c
Setting a simple breakpoint:
TR I PSWA <address>
To debug a particular function try:
To display memory that was mapped using the current PSW's mapping try:
D <range>
To make VM display a message each time it hits a particular address and continue try:
There are other complex options to display if you need to get at say home space but are in primary space the easiest thing to do is to temporarily
modify the PSW to the other addressing mode, display the stuff and then restore it.
If you want to issue a debugger command without halting your virtual machine with the PA1 key, then try prefixing the command with #CP:
#cp tr i pswa 2000
Also suffixing most debugger commands with RUN will cause them not to stop just display the mnemonic at the current instruction on the console. If you have several breakpoints you want to put into your program and you get fed up of cross referencing with System.map you can do the following trick for several symbols.:
grep do_signal System.map
which emits the following among other things:
0001f4e0 T do_signal
Now you can do:
TR I PSWA 0001f4e0 cmd msg * do_signal
This sends a message to your console each time do_signal is entered. (As an aside I wrote a perl script once which automatically generated a REXX script with breakpoints on every kernel procedure. This isn't a good idea because there are thousands of these routines and VM can only set 255 breakpoints at a time, you nearly had to spend as long pruning the file down as you would enter the messages by hand). However, the trick might be useful for a single object file.
If you get a crash which says something like illegal operation or specification exception followed by a register dump You can restart Linux and trace these using the tr prog <range | value> option.
The most common ones you will normally be tracing for is:
|
1 |
operation exception |
|
2 |
privileged operation exception |
|
4 |
protection exception |
|
5 |
addressing exception |
|
6 |
specification exception |
|
10 |
segment translation exception |
|
11 |
page translation exception |
The full list of these is on page 22 of the current ESA Reference Summary. For example:
On starting VM you are initially in the INITIAL trace set. You can do a Q TR to verify this. If you have a complex tracing situation where you wish to wait for instance till a driver is open before you start tracing IO, but know in your heart that you are going to have to make several runs through the code till you
have a clue whats going on.
What you can do is:
TR I PSWA <Driver open address>
Enter b to continue until the breakpoint is reached. Now do your:
TR GOTO B
TR IO 7c08-7c09
or whatever and trace tour IOTo got back to the initial trace set do:
TR GOTO INITIAL
and the TR I PSWA <Driver open address> will be the only active breakpoint again.
Syscalls are implemented on Linux for S390 by the Supervisor call instruction (SVC) there 256 possibilities of these as the instruction is made up of a 0x0a opcode and the second byte being the syscall number. They are traced using the simple command:
TR SVC <Optional value or range>
The syscalls are defined in linux/include/asm-s390/unistd.h. For example, to trace all file opens just do:
TR SVC 5
(as this is the syscall number of open)VM's ability to trace branch operations allows the production of system flow data. The output can (and is) quite voluminous but can be made human-friendly by the following process.
#CP TR BR PRINT
#CP SP P <user>
#CP TR END #CP CLOSE P
/* */
parse upper arg Option .
signal on SYNTAX
MaxSym = 0
Cache. = ''
if Option <> '' then
Stage = ''
else
Stage = '| nlocate /memset/',
'| nlocate /memcpy/',
'| nlocate /memcmp/',
'| nlocate /update_wall_time/',
'| nlocate /printk/',
'| nlocate /strcpy/',
'| nlocate /strncpy/',
'| nlocate /strcmp/',
'| nlocate /strncmp/',
'| nlocate /strchr/',
'| nlocate /strlen/',
'| nlocate /ExternalException/',
'| nlocate /External+/',
'| nlocate /do_timer/',
'| nlocate /vsprintf/',
'| nlocate /set_bit/',
'| nlocate /free_pages/',
'| nlocate /mem_init/'
'PIPE (name READ_MAP)',
'| ftp ftp://<user>:<password>@<host.domain>/linux/System.map binary',
'| xlate from 437 to 1047',
'| deblock c',
'| drop 1',
'| strip',
'| locate 1',
'| nfind U' ||,
'| spec w1 x2c 1 w1-* nw',
'| stem Map.'
'PIPE (name READ_TRACE end ?)',
'| reader',
'| mctoasa',
'| spec 2-* 1',
'| a: locate /BASR/',
'| b: faninany',
'| spec w2-4 1 w6 nw',
'| stem Trace.',
'? a:',
'| c: locate /LPSW/',
'| b:',
'? c:',
'| locate / 07FE /',
'| b:'
do I_Trace = 1 to Trace.0
if ((I_Trace // 5000) = 0) then
say '...'I_Trace
parse var Trace.I_Trace From Branch BrType To
if (Cache.From = '') then
do
FromSym = GET_ADDR(From,'F')
Cache.From = FromSym
end
else
FromSym = Cache.From
if (Cache.To = '') then
do
ToSym = GET_ADDR(To,'T')
Cache.To = ToSym
end
else
ToSym = Cache.To
select
when BrType = '0D1E' then
Branch = '<---'
when BrType = '0DEF' then
Branch = '--->'
when BrType = '07FE' then
Branch = '<---'
otherwise
Branch = '--->'
end
Flow.I_Trace = FromSym LEFT(Branch,8) ToSym
end
Flow.0 = Trace.0
'PIPE (name WRITE_FLOW end ?)',
'| stem Flow.',
'| spec w1 1.'MaxSym 'w2-* nw',
Stage,
'| spec 1-* 5',
'| > LINUX FLOW A'
exit
GET_ADDR:
parse arg VAddr,Type
parse var VAddr Addr"'"
XAddr = X2C(Addr)
Target = Map.0
NewTarget = 1
Disp = Map.0 % 2
LastLow = Target
do forever
parse var Map.Target 1 XSym 5 . . Symbol
if XAddr = XSym then
do
LastLow = Target
leave
end
if XAddr < XSym then
do
NewTarget = Target - Disp
if (LastLow = NewTarget) then
leave
LastLow = NewTarget
end
else
NewTarget = Target + Disp
Disp = Disp % 2
if (Disp < 1) then
Disp = 1
Target = NewTarget
end
parse var Map.LastLow 1 XSym 5 . . Symbol
Disp = X2D(Addr) - C2D(XSym)
if Disp <> 0 then
Symbol = Symbol'+'D2X(Disp)
if ((LENGTH(Symbol) > MaxSym) & (Type = 'F')) then
MaxSym = LENGTH(Symbol)
return Symbol
SYNTAX:
say 'Error:' ERRORTEXT(Rc) 'at line' Sigl
say SOURCELINE(Sigl)
trace ?r; nop
exit -1
Q CPUS
displays all the CPU's available to your virtual machineQ CPU
CPU <desired cpu no>
CPU 01 TR I R 2000.3000
shutdown -h now
or halt.Do a Q CPUS to find out how many CPUs you have; detach each one of them from your virtual machine except CPU 0 by issuing:
DETACH CPU 01-<number of CPUs in configuration>
and re-boot Linux.
Currently, text cannot be displayed in ASCII under the VM debugger (I love EBDIC too), I have written this little program which will convert a command line of hex digits to ASCII text which can be compiled under Linux and you can copy the hex digits from your x3270 terminal to your xterm if you are debugging from a Linux box.
This is quite useful when looking at a parameter passed in as a text string under VM (unless you are good at decoding ASCII in your head). For example, consider tracing an open syscall:
TR SVC 5
We have stopped at a breakpoint
000151B0' SVC 0A05 - 0001909A' CC 0
Use D P SVC to check the SVC old PSW in the prefix area and see was it from user-space (for the layout of the prefix area consult page18 of the ESA 390 Reference Summary if you have it available).
SVC 0005 20 OLD 070C2000 800151B2 60 NEW 04080000 8001909A
The problem state bit wasn't set and it's also too early in the boot sequence for it to be a user-space SVC if it was we would have to temporarily switch the PSW to user space addressing so we could get at the first parameter of the open in gpr2. To display the parameter:
D 0.20;BASE2 V00014CB4 2F646576 2F636F6E 736F6C65 00001BF5 V00014CC4 FC00014C B4001001 E0001000 B8070707
Now copy the text till the first 00 hex (which is the end of the string) to an xterm and do hex2ascii on it:
hex2ascii 2F646576 2F636F6E 736F6C65 00
The resulting output is:
Decoded Hex:=/ d e v / c o n s o l e 0x00
We were opening the console device.
You can compile the code below yourself for practice :-),
/*
* hex2ascii.c
* a useful little tool for converting a hexadecimal command line to ascii
*
* Author(s): Denis Joseph Barrow (djbarrow@de.ibm.com,barrow_dj@yahoo.com)
* (C) 2000 IBM Deutschland Entwicklung GmbH, IBM Corporation.
*/
#include <stdio.h
int main(int argc,char *argv[])
{
int cnt1,cnt2,len,toggle=0;
int startcnt=1;
unsigned char c,hex;
if(argc1&&(strcmp(argv[1],"-a")==0))
startcnt=2;
printf("Decoded Hex:=");
for(cnt1=startcnt;cnt1<argc;cnt1++)
{
len=strlen(argv[cnt1]);
for(cnt2=0;cnt2<len;cnt2++)
{
c=argv[cnt1][cnt2];
if(c='0'&&c<='9')
c=c-'0';
if(c='A'&&c<='F')
c=c-'A'+10;
if(c='a'&&c<='F')
c=c-'a'+10;
switch(toggle)
{
case 0:
hex=c<<4;
toggle=1;
break;
case 1:
hex+=c;
if(hex<32||hex127)
{
if(startcnt==1)
printf("0x%02X ",(int)hex);
else
printf(".");
}
else
{
printf("%c",hex);
if(startcnt==1)
printf(" ");
}
toggle=0;
break;
}
}
}
printf("\n");
} Alternatively, the following CMS PIPELINE will achieve the same thing:
/* */ parse arg XString 'PIPE (name E2A)', '| var Xstring', '| change / //', /* Remove any blanks within string */ '| spec 1-* x2c 1', /* Convert graphic hex to binary */ '| xlate from 437 to 1047', /* Choose the code-page you prefer */ '| cons'
Here are the tricks I use 9 out of 10 times it works pretty well.
This can happen when an exception happens in the kernel and the kernel is entered twice if you reach the NULL pointer at the end of the back chain you should be able to sniff further back if you follow the following tricks.
Here is some practice.
GPR 0 = 00000001 00156018 0014359C 00000000 GPR 4 = 00000001 001B8888 000003E0 00000000 GPR 8 = 00100080 00100084 00000000 000FE000 GPR 12 = 00010400 8001B2DC 8001B36A 000FFED8
D 0.40;BASEF V000FFED8 000FFF38 8001B838 80014C8E 000FFF38 V000FFEE8 00000000 00000000 000003E0 00000000 V000FFEF8 00100080 00100084 00000000 000FE000 V000FFF08 00010400 8001B2DC 8001B36A 000FFED8
d 000FFF38.40
V000FFF38 000FFFA0 00000000 00014995 00147094 V000FFF48 00147090 001470A0 000003E0 00000000 V000FFF58 00100080 00100084 00000000 001BF1D0 V000FFF68 00010400 800149BA 80014CA6 000FFF38
This displays a 2nd return address of 80014CA6
V000FFFA0 04B52002 0001107F 00000000 00000000 V000FFFB0 00000000 00000000 FF000000 0001107F V000FFFC0 00000000 00000000 00000000 00000000 V000FFFD0 00010400 80010802 8001085A 000FFFA0
Our 3rd return address is 8001085A. As the 04B52002 looks suspiciously like rubbish it is fair to assume that the kernel entry routines for the sake of optimization do not set up a backchain.
grep -i 0001b3 System.map
Outputs among other things:
0001b304 T cpu_idle
So 8001B36A is cpu_idle+0x66 (quiet the cpu is asleep, don't wake it!)
grep -i 00014 System.map
Produces among other things
00014a78 T start_kernel
So 0014CA6 is start_kernel+0x22e.
grep -i 00108 System.map
This produces:
00010800 T _stext
So 8001085A is _stext+0x5a
I am not going to give a course in 390 IO architecture as this would take me quite a while and I'm no expert. Instead I'll give a 390 IO architecture summary for Dummies if you have the ESA principles of operation available read this instead. If nothing else you may find a few useful keywords in here and be able to use them on a web search engine like Altavista to find more useful information.
Unlike other bus architectures modern 390 systems do their IO using mostly fibre optics and devices such as tapes and disks can be shared between several mainframes, also S390 can support up to 65536 devices while a high end PC based system might be choking with around 64. Here is some of the common IO terminology.
|
Subchannel |
This is the logical number most IO commands use to talk to an IO device there can be up to 0x10000 (65536) of these in a configuration typically there is a few hundred. Under VM for simplicity they are allocated contiguously, however on the native hardware they are not they typically stay consistent between boots provided no new hardware is inserted or removed. Under Linux for 390 we use these as IRQ's and also when issuing an IO command (CLEAR SUBCHANNEL, HALT SUBCHANNEL, MODIFY SUBCHANNEL, RESUME SUBCHANNEL, START SUBCHANNEL, STORE SUBCHANNEL and TEST SUBCHANNEL) we use this as the ID of the device we wish to talk to. The most important of these instructions are START SUBCHANNEL (to start IO), TEST SUBCHANNEL (to check whether the IO completed successfully), and HALT SUBCHANNEL (to kill IO). A subchannel can have up to 8 channel paths to a device this offers redundancy if one is not available. |
|
Device Number |
This number remains static and Is closely tied to the hardware, there are 65536 of these also they are made up of a CHPID (Channel Path ID, the most significant 8 bits) and another LSB 8 bits. These remain static even if more devices are inserted or removed from the hardware, there is a 1 to 1 mapping between Subchannels and Device Numbers provided devices are not inserted or removed. |
|
Channel Control Words |
CCWS are linked lists of instructions initially pointed to by an operation request block (ORB), which is initially given to Start Subchannel (SSCH) command along with the subchannel number for the IO subsystem to process while the CPU continues executing normal code. These come in two flavors, Format 0 (24 bit for backward) compatibility and Format 1 (31 bit). These are typically used to issue read and write (and many other instructions) they consist of a length field and an absolute address field. For each IO typically get 1 or 2 interrupts one for channel end (primary status) when the channel is idle and the second for device end (secondary status). Sometimes you get both concurrently, you check how the IO went on by issuing a TEST SUBCHANNEL at each interrupt, from which you receive an Interruption response block (IRB). If you get channel and device end status in the IRB without channel checks etc. your IO probably went okay. If you didn't you probably need to examine the IRB and extended status word etc. If an error occurs, then more sophisticated control units have a facility known as concurrent sense. This means that if an error occurs Extended sense information will be presented in the Extended status word in the IRB if not you have to issue a subsequent SENSE CCW command after the test subchannel. |
|
TPI |
Test pending interrupt can also be used for polled IO but in multitasking multiprocessor systems it isn't recommended except for checking special cases (i.e. non-looping checks for pending IO etc.). |
|
STSCH/MSCH |
Store Subchannel and Modify Subchannel can be used to examine and modify operating characteristics of a subchannel (e.g. channel paths). |
|
Sysplex |
S390's Clustering Technology |
|
QDIO |
S390's new high speed IO architecture to support devices such as gigabit Ethernet, this architecture is also designed to be forward compatible with up and coming 64 bit machines. |
Input Output Processors (IOP's) are responsible for communicating between the mainframe CPU's and the channel and relieve the mainframe CPU's from the burden of communicating with IO devices directly, this allows the CPU's to concentrate on data processing.
IOP's can use one or more links (known as channel paths) to talk to each IO device. It first checks for path availability and chooses an available one, then starts (and sometimes terminates IO). There are two types of channel path ESCON and the Parallel IO interface.
IO devices are attached to control units. Control units provide the logic to interface the channel paths and channel path IO protocols to the IO devices. They can be integrated with the devices or housed separately and often talk to several similar devices (typical examples would be RAID controllers or a control unit which connects to 1000 3270 terminals).
+---------------------------------------------------------------+
| +-----+ +-----+ +-----+ +-----+ +----------+ +----------+ |
| | CPU | | CPU | | CPU | | CPU | | Main | | Expanded | |
| | | | | | | | | | Memory | | Storage | |
| +-----+ +-----+ +-----+ +-----+ +----------+ +----------+ |
|---------------------------------------------------------------+
| IOP | IOP | IOP |
|---------------------------------------------------------------|
| C | C | C | C | C | C | C | C | C | C | C | C | C | C | C | C |
+---------------------------------------------------------------+
|| ||
|| Bus & Tag Channel Path || ESCON
|| ====================== || Channel
|| || || || Path
+----------+ +----------+ +----------+
| | | | | |
| CU | | CU | | CU |
| | | | | |
+----------+ +----------+ +----------+
| | | | |
+----------+ +----------+ +----------+ +----------+ +----------+
|I/O Device| |I/O Device| |I/O Device| |I/O Device| |I/O Device|
+----------+ +----------+ +----------+ +----------+ +----------+
CPU = Central Processing Unit
C = Channel
IOP = IP Processor
CU = Control Unit
The 390 IO systems come in 2 flavors the current 390 machines support both the older 360 and 370 interface, sometimes called the parallel I/O interface, sometimes called Bus-and Tag and sometimes Original Equipment Manufacturers Interface (OEMI).
This byte wide parallel channel path/bus has parity and data on the "Bus" cable and control lines on the "Tag" cable. These can operate in byte multiplex mode for sharing between several slow devices or burst mode and monopolize the channel for the whole burst. Upto 256 devices can be addressed on one of these ables. These cables are about one inch in diameter. The maximum unextended length supported by these cables is 125 Meters but this can be extended up to 2km with a fiber optic channel extended such as a 3044. The maximum burst speed supported is 4.5 megabytes per second however some really old processors support only transfer rates of 3.0, 2.0 and 1.0 MB/sec. One of these paths can be daisy chained to up to 8 control units.
IBM introduced ESCON, which is fiber optic based, in 1990. It uses 2 fiber optic cables and uses either LEDs or lasers for communication at a signaling rate of up to 200 megabits/sec. As 10 bits are transferred for every 8 bits of information this drops to 160 megabits/sec and to 18.6 Megabytes/sec once control information and CRC are added. ESCON only operates in burst mode.
ESCONs typical maximum cable length is 3km for the LED version and 20km for the laser version known as XDF (extended distance facility). This can be further extended by using an ESCON director which triples the above mentioned ranges. Unlike Bus and Tag as ESCON is serial. It uses a packet switching architecture. The standard Bus and Tag control protocol is however present within the packets. Up to 256 devices can be attached to each control unit that uses one of these interfaces.
A new fiber architecture has been released by IBM called FICON which improves on the performance of ESCON.
Now we are ready to go on with IO tracing commands under VM. First, a few self explanatory queries:
Q OSA Q CTC Q DISK Q DASD
Q OSA on my machine returns
OSA 7C08 ON OSA 7C08 SUBCHANNEL = 0000 OSA 7C09 ON OSA 7C09 SUBCHANNEL = 0001 OSA 7C14 ON OSA 7C14 SUBCHANNEL = 0002 OSA 7C15 ON OSA 7C15 SUBCHANNEL = 0003
Now using the device numbers returned by this command we will trace the Io starting up on the first devices 7c08 and 7c09. In our simplest case we can trace the start subchannels:
TR SSCH 7C08-7C09
Or the halt subchannels
TR HSCH 7C08-7C09
You can also trace MSCH's ,STSCH's, but I think you can guess the rest.
Ingo's favourite trick is tracing all the IO's and CCWS and spooling them into the reader of another VM guest so he can ftp the logfile back to his own machine. I'll do a small bit of this and give you a look at the output.
SP PRT TO *
TR IO 7c08-7c09 INST INT CCW PRT RUN
TR END
C PRT
RDRLIST
RECEIVE / LOG TXT A1 ( replace
00020942' SSCH B2334000 0048813C CC 0 SCH 0000 DEV 7C08 < CPA 000FFDF0 PARM 00E2C9C4 KEY 0 FPI C0 LPM 80 CCW 000FFDF0 E4200100 00487FE8 0000 E4240100 ........ IDAL 43D8AFE8 IDAL 0FB76000 00020B0A' I/O DEV 7C08 - 000197BC' SCH 0000 PARM 00E2C9C4 00021628' TSCH B2354000 00488164 CC 0 SCH 0000 DEV 7C08 CCWA 000FFDF8 DEV STS 0C SCH STS 00 CNT 00EC KEY 0 FPI C0 CC 0 CTLS 4007 00022238' STSCH B2344000 00488108 CC 0 SCH 0000 DEV 7C08
Note, compiling for debugging with gdb works better without optimization (see Compiling programs for debugging).
gdb <victim program <optional corefile>
help: gives help on commands. For example:
help
help display
Note gdb's online help is very good and we advise you to use it.
disassemble
(specifying no parameters will disassemble the current function)p/x $sp
will display the stack pointerdisplay/x $pc
will display the program counterset <variable=value>
set argc=100
set $pc=0
break main break *$pc break *0x400618
rbr 390
Will set a breakpoint with all functions with 390 in their name.
delete 1
will delete the first breakpointwatch cnt,
will watch the variable cnt till it changes. As an aside unfortunately gdb's, architecture independent watchpoint code is inconsistent and not very good. Watchpoints usually work but not always.define d stepi disassemble $pc $pc+10 end define e nexti disassemble $pc $pc+10 end
list lists current function source
list 1,10 list first 10 lines of current file.
list test.c:1,10
directory //
(gdb) call printf("hello world")
Outputs:
$1 = 11
You might now be thinking that the line above didn't work, something extra had to be done.
(gdb) call fflush(stdout)
hello world$2 = 0
As an aside the debugger also calls malloc and free under the hood to make space for the "hello world" string.
A typical .gdbinit file might be:
break main run break runtime_exception cont
p/x (*($sp+56))&0x7fffffff
get the first backchain.This outputs:
$5 = 0x528f18
(On my machine that is.)
info symbol (*($sp+56))&0x7fffffff
You might see something like:
rl_getc + 36 in section .text
telling you what is located at address 0x528f18p/x (*(*$sp+56))&0x7fffffff
This outputs:
$6 = 0x528ed0
info symbol (*(*$sp+56))&0x7fffffff
rl_read_key + 180 in section .text
p/x (*(**$sp+56))&0x7fffffff
and so on.
From your Linux box do:
man gdb or info gdb
A core dump is a file generated by the kernel ( if allowed ) which contains the registers, and all active pages of the program which has crashed. From this file gdb will allow you to look at the registers and stack trace and memory of the program as if it just crashed on your system. It is usually called core and created in the current working directory. This is very useful in that a customer can mail a core dump to a technical support department and the technical support department can reconstruct what happened. Provided the have an identical copy of this program with debugging symbols compiled in and the source base of this build is available.
In short it is far more useful than something like a crash log could ever hope to be.
In theory all that is missing to restart a core dumped program is a kernel patch which will do the following.
Probably because you haven't used the command:
ulimit -c unlimited
to allow core dumps, now do:
ulimit -a
to verify that the limit was accepted.
ulimit -c unlimited gdb
To launch gdb (my victim application).
ps -aux | grep gdb kill -SIGSEGV <gdb's pid >
or alternatively use:
killall -SIGSEGV gdb
if you have the killall command.
./gdb ./gdb core
The following will be displayed:
GNU gdb 4.18 Copyright 1998 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "s390-ibm-linux"... Core was generated by `./gdb'. Program terminated with signal 11, Segmentation fault. Reading symbols from /usr/lib/libncurses.so.4...done. Reading symbols from /lib/libm.so.6...done. Reading symbols from /lib/libc.so.6...done. Reading symbols from /lib/ld-linux.so.2...done. #0 0x40126d1a in read () from /lib/libc.so.6 Setting up the environment for debugging gdb. Breakpoint 1 at 0x4dc6f8: file utils.c, line 471. Breakpoint 2 at 0x4d87a4: file top.c, line 2609. (top-gdb) info stack #0 0x40126d1a in read () from /lib/libc.so.6 #1 0x528f26 in rl_getc (stream=0x7ffffde8) at input.c:402 #2 0x528ed0 in rl_read_key () at input.c:381 #3 0x5167e6 in readline_internal_char () at readline.c:454 #4 0x5168ee in readline_internal_charloop () at readline.c:507 #5 0x51692c in readline_internal () at readline.c:521 #6 0x5164fe in readline (prompt=0x7ffff810 "\177¢·¢xx\177¢·¢w¢X\177¢·¢xx¢@") at readline.c:349 #7 0x4d7a8a in command_line_input (prompt=0x564420 "(gdb) ", repeat=1, annotation_suffix=0x4d6b44 "prompt") at top.c:2091 #8 0x4d6cf0 in command_loop () at top.c:1345 #9 0x4e25bc in main (argc=1, argv=0x7ffffdf4) at main.c:635
This is a program which lists the shared libraries which a library needs. For example:
ldd ./gdb
Outputs:
libncurses.so.4 = /usr/lib/libncurses.so.4 (0x40018000) libm.so.6 = /lib/libm.so.6 (0x4005e000) libc.so.6 = /lib/libc.so.6 (0x40084000) /lib/ld-linux.so.2 = /lib/ld-linux.so.2 (0x40000000)
As modules are dynamically loaded into the kernel their address can be anywhere to get around this use the -m option with insmod to emit a load map which can be piped into a file if required.
This is a filesystem created by the kernel with files which are created on demand by the kernel if read, or can be used to modify kernel parameters. It is a powerful concept. For example:
cat /proc/sys/net/ipv4/ip_forward
On my machine outputs:
0
This tells me that ip_forwarding is not on. To switch it on I can do:
echo 1 /proc/sys/net/ipv4/ip_forward
cat it again:
cat /proc/sys/net/ipv4/ip_forward 1
That is, IP forwarding is now on.
There is a lot of useful info in here best found by going in and having a look around, so I'll take you through some entries I consider important.
cd /proc/1 cat cmdline init [2]
cd /proc/1/fd
This contains numerical entries of all the open files.
cat /proc/29/maps 00400000-00478000 r-xp 00000000 5f:00 4103 /bin/bash 00478000-0047e000 rw-p 00077000 5f:00 4103 /bin/bash 0047e000-00492000 rwxp 00000000 00:00 0 40000000-40015000 r-xp 00000000 5f:00 14382 /lib/ld-2.1.2.so 40015000-40016000 rw-p 00014000 5f:00 14382 /lib/ld-2.1.2.so 40016000-40017000 rwxp 00000000 00:00 0 40017000-40018000 rw-p 00000000 00:00 0 40018000-4001b000 r-xp 00000000 5f:00 14435 /lib/libtermcap.so.2.0.8 4001b000-4001c000 rw-p 00002000 5f:00 14435 /lib/libtermcap.so.2.0.8 4001c000-4010d000 r-xp 00000000 5f:00 14387 /lib/libc-2.1.2.so 4010d000-40111000 rw-p 000f0000 5f:00 14387 /lib/libc-2.1.2.so 40111000-40114000 rw-p 00000000 00:00 0 40114000-4011e000 r-xp 00000000 5f:00 14408 /lib/libnss_files-2.1.2.so 4011e000-4011f000 rw-p 00009000 5f:00 14408 /lib/libnss_files-2.1.2.so 7fffd000-80000000 rwxp ffffe000 00:00 0
Showing us the shared libraries init uses where they are in memory and memory access permissions for each virtual memory area.
Name: init State: S (sleeping) Pid: 1 PPid: 0 Uid: 0 0 0 0 Gid: 0 0 0 0 Groups: VmSize: 408 kB VmLck: 0 kB VmRSS: 208 kB VmData: 24 kB VmStk: 8 kB VmExe: 368 kB VmLib: 0 kB SigPnd: 0000000000000000 SigBlk: 0000000000000000 SigIgn: 7fffffffd7f0d8fc SigCgt: 00000000280b2603 CapInh: 00000000fffffeff CapPrm: 00000000ffffffff CapEff: 00000000fffffeff User PSW: 070de000 80414146 task: 004b6000 tss: 004b62d8 ksp: 004b7ca8 pt_regs: 004b7f68 User GPRS: 00000400 00000000 0000000b 7ffffa90 00000000 00000000 00000000 0045d9f4 0045cafc 7ffffa90 7fffff18 0045cb08 00010400 804039e8 80403af8 7ffff8b0 User ACRS: 00000000 00000000 00000000 00000000 00000001 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 Kernel BackChain CallChain BackChain CallChain 004b7ca8 8002bd0c 004b7d18 8002b92c 004b7db8 8005cd50 004b7e38 8005d12a 004b7f08 80019114
Showing among other things memory usage and status of some signals and the processes' registers from the kernel task_structure as well as a backchain which may be useful if a process crashes in the kernel for some unknown reason.
Use the -x option to trace the script: bash -x <scriptname>. For example:
bash -x /usr/bin/bashbug + MACHINE=i586 + OS=linux-gnu + CC=gcc + CFLAGS= -DPROGRAM='bash' -DHOSTTYPE='i586' -DOSTYPE='linux-gnu' -DMACHTYPE='i586-pc-linux-gnu' -DSHELL -DHAVE_CONFIG_H -I. -I. -I./lib -O2 -pipe + RELEASE=2.01 + PATCHLEVEL=1 + RELSTATUS=release + MACHTYPE=i586-pc-linux-gnu
Use the -d option of perl to invoke the interactive debugger: perl -d <scriptname>
Use: jdb <filename> to invoke another fully interactive gdb style debugger. Type "?" for help when the debugger is invoked.
![]()
Without a telnet connection into your Linux system you cannot do much. Unfortunately getting an IP address and routing in place is not always easy to arrange on short notice.
The following describes a very minimal network when running under VM. We created a private subnet for the Linux virtual machine(s) and use CMS Pipelines TCP/IP support to connect that subnet to your primary TCP/IP stack.
This approach does not require any changes to your production TCP/IP.
In the examples setup I'll use the following userids:
The alternative stack. A normal class G userid with a R/O link to the TCPIP 591 disk and IUCV ALLOW and IUCV ANY directory statements.
Your production stack.
Ordinary class G userid that runs a pipeline to connect the two networks.
One of the virtual machines running Linux
The updates to configuration files are described within this section.
:nick.LINUXTCP :type.server :class.stack :owner.RVDHEIJ :diskwarn.
When I defined this I didn't have the IUCV options in the directory so I did a CTC link. You should be able to do an IUCV link as well.
device dev_700 CTC 700 link link_linuxvm ctc 1 dev_700
The 192.168.16 subnet is one of the private subnets that you can use internally but that can not go out to the Internet.
home 192.168.16.254 link_linuxvm
The following will let you tn3270 from your Linux virtual machine to your VM system, if you need that.
port 23 tcp intclien internalclientparms port 23 endinternalclientparms
When you add move Linux guests you need to think about routing.
gateway 192.168.16.2 = link_linuxvm defaultsize host bsdroutingparms true endbsdroutingparms start dev_700
This one works for me.
/* */ 'VMLINK TCPIP 591 TCPIP 592 ( NONAMES' 'DEF CTC 700' ; 'COUPLE 700 TO LINUXVM 700' 'DEF CTC 701' ; 'COUPLE 701 TO LINUXVM 701' 'TCPRUN'
Note that the CTC's are cross-connected here. Your LINUXVM userid should do something similar so you get yout connection also when LINUXVM starts up after LINUXTCP.
Now put a TCPIP DATA on your A-disk with tcpipuserid linuxtcp
First try to ping 192.168.16.254 (the stack itself). When that works you should be able to ping 192.168.16.2 (to verify the connection to your Linux virtual machine).
The next test could be to telnet or ftp to 192.168.16.2 (still using the modified TCPIP DATA file.
The WARPHOLE userid runs the WARPHOLE EXEC. The program is in fact a stripped down version of TCPSNIFF from John Hartmann.
The core pipeline has a number of segments like this:
\ tcplisten <i>from-port</i> user tcpip reuseaddr | spawner tcpclient linuxvm <i>target</i> user linuxtcp
You need one of those for each port on the production network that you want to connect to your Linux virtual machine. If you reverse them you can make a port on the LINUXTCP stack that goes out.
/* WARPHOLE EXEC TCP/IP Socket Relay */
/* Author: Rob van der Heij, 27 Oct 1999 */
ports = '23 25 80'
'PIPE(end \ name WARPHOLE.EXEC:3)',
'\ var ports',
'| split',
'| spec ,tcplisten 100, 1 w1 n ,user tcpip reuseaddr, nw x4f nw',
',spawner tcpclient 192.168.16.2, nw w1 nw ,user linuxtcp, nw',
'x4f nw ,cons, nw',
'| join * ,\\,',
'| var pipe1'
'PIPE (end \ name WARPHOLE.EXEC:7)' pipe1
return rc
/* SPAWNER REXX Spawn a subprocess like InetD does it */
/* Author: Rob van der Heij, 27 Oct 1999 */
signal on error
arg process /* Process plus arguments */
do forever
'peekto req' /* Wait for connection request */
'callpipe (end \ name SPAWNER.REXX:4)',
'\ var req ', /* Take the request */
'| spec 65.16 1', /* Requester address & port */
'| socka2ip', /* Make it readable */
'| spec w3 1 ,:, n w2 n',
'| var whosthat'
say whosthat 'calling' process
'addpipe (end \ name SPAWNER.REXX:9)',
'\ *.output: ',
'| i: fanin ',
'| tcpdata ',
'|' process ,
'| elastic ',
'| i:'
'callpipe( end \) *: | take',
'| c: count lines',
'| *:', /* Feed it one request */
'\ c: | var cnt'
if cnt = 0 then 'readto' /* Reject the connection */
'sever output' /* Cut it loose */
end
error: return rc * ( rc ^= 12 )
Rename your modified TCPIP DATA file and check for listening ports:
netstat ( select user warphole
This should give you something like this
VM TCP/IP Netstat Level 320 Active Transmission Blocks User Id Conn Local Socket Foreign Socket State ---- -- ---- ----- ------ ------- ------ ----- WARPHOLE 1860 *..10025 *..* Listen WARPHOLE 1234 *..10023 *..* Listen WARPHOLE 1363 *..10080 *..* Listen
From VM you can now telnet 127.0.0.1 10023 to logon to Linux, or from your workstation to your production stack port 10023.
Remember you telnet into Linux with a VT220 emulator or such, not a tn3270. I found IVT very useful (search on http://www.shareware.com
for VT220).![]()
This section describes the packages that we've ported to Linux/390 and any special steps that needed taking.
-O1 and not -O2 or -O3 when setting optimization on compiles.
This can be circumvented if you:
-fno-strict-aliasing to the CFLAGS, or,
Also note that GCC will use all 16 floating point registers that are availableon IEEE-enabled machines. If your machine is not IEEE-capable then it will be emulated in software for you.
/etc/ld.so.conf with /usr/local/lib and run ldconfig -v.This is REXX for UNIX systems. No other changes than specified in the "Common Issues" section need to be undertaken. The build and install will complete without a problem.
----- REXXCPS 2.1 -- Measuring REXX clauses/second -----
REXX version is: REXX-Regina_0_08g 4.80 7 Aug 1999
System is: UNIX
Averaging: 10 measures of 30 iterations
Performance: 113230 REXX clauses per second
Compare this to the native CMS interpreter on the same CPU:
----- REXXCPS 2.1 -- Measuring REXX clauses/second -----
REXX version is: REXX370 4.01 20 Dec 1996
System is: CMS
Averaging: 10 measures of 30 iterations
Performance: 74751 REXX clauses per second
These results do not differ from the Linux/Intel results.
========================== ../trip/arith.rexx ==========================
adding, multiplication, division, modulus, reminder, power, exponential,
numeric,
========================= ../trip/builtin.rexx =========================
REXX-Regina_0_08g 4.80
abbrev, abs, address, arg, b2x, bitand, bitor, bitxor, c2d, c2x, center,
changestr, compare, copies, countstr, datatype,
first= /1/
second=/0/
FuncTrip: error in 286: call ch datatype('123.0000003','W'), '0'
first= /1/
second=/0/
FuncTrip: error in 287: call ch datatype('123.0000004','W'), '0'
delstr, delword, digits,
d2c, d2x, errortext, form, format, fuzz, insert, lastpos, left, length, max,
min, overlay, pos, reverse, right, sign,
first= /-1/
second=/0/
FuncTrip: error in 645: call ch sign('-0'), 0
sourceline,
first= /1158/
second=/1/
FuncTrip: error in 655: call ch sourceline(), lines(srcfile) /* don't work for stdin */
space, strip, substr,
subword, symbol, translate, trunc, value, verify, word, wordindex,
wordlength, wordpos, words, xrange, x2c, x2d, justify,
========================== ../trip/files.rexx ==========================
simple, read, eof, zero_line, truncate, charin, faking, nofake, halfline,
crp/cwp, notready, holes, linecnt, flush, repos, persist/eof, stdio,
longlines, many, stick, close, empty_out,
========================== ../trip/funcs.rexx ==========================
arguments, comments, nullargs, labels, external, result, builtin, whole,
========================= ../trip/lexical.rexx =========================
========================= ../trip/limits.rexx ==========================
args, levels, comments, strings, hexstrings, symbols,
========================= ../trip/signal.rexx ==========================
halt, novalue, execution, ...
Tripped in line 275: CALL ON HALT evalueate expression twice?.
(triggered, return, rc/syntax, ...
Tripped in line 353: SYNTAX condition was not triggered.
(lineno1, lineno2,
in_delay, ...
Tripped in line 436: Does not reset DELAY mode with CALL ON.
(stacking, ...
Tripped in line 458: did not trigger both ERROR and HALT.
(result, sh: .//rc: cannot execute binary file
...
Tripped in line 476: ERROR not properly called.
( ...
Tripped in line 490: RESULT was set at return from CALL ON.
(after_delay, ...
Tripped in line 521: CALL ON HALT did not remove DELAYed mode.
( ...
Tripped in line 508: CALL ON HALT does not seem to work.
(subrout, sh: .//rc: cannot execute binary file
sh: .//rc: cannot execute binary file
delay/sub, sh: .//rc: cannot execute binary file
sh: .//rc: cannot execute binary file
ctc/sub, sh: .//rc: cannot execute binary file
sh: .//rc: cannot execute binary file
on/off, sh: .//rc: cannot execute binary file
sigl/halt, ...
Tripped in line 673: SIGL not set during CALL ON HALT.
(symbols, drop,
========================== ../trip/stack.rexx ==========================
push, queue, queued, commands,
========================== ../trip/stats.rexx ==========================
general, address, arg, call, do-loops, drop, if, iterate, leave, parsing,
procedure, select, signal, trace,
========================== ../trip/time.rexx ===========================
date, time,
========================== ../trip/trip.rexx ===========================
comments, strings, hexstrings, binstrings, dataformats, continuations,
expr, random, arrays, lexical, labels, numbers, functions, recursing,
======================== ../trip/variable.rexx =========================
drop,
THE: is The Hessling Editor. This is XEDIT for UNIX systems. No other changes than specified in the "Common Issues" section need to be undertaken. The build and install will complete without a problem. I included the --with-regina configuration option to enable THE macros written in REXX.
No other changes than specified in the "Common Issues" section need to be undertaken. The build and install will complete without a problem.
No other changes than specified in the "Common Issues" section need to be undertaken. The build and install will complete without a problem.
No other changes than specified in the "Common Issues" section need to be undertaken. The build and install will complete without a problem.
No changes need to be undertaken. The build and install will complete without a problem.
# @(#)Linux 8.4 (Berkeley) 3/22/1998 define(`confSTDIR', `/etc') define(`confHFDIR', `/usr/lib') define(`confDEPEND_TYPE', `CC-M') define(`confMANROOT', `/usr/man/man') define(`confCC', `gcc') define(`confENVDEF', `-O1 -I/usr/local/include -fno-caller-saves')
divert(-1) # # Copyright (c) 1998 Sendmail, Inc. All rights reserved. # Copyright (c) 1983 Eric P. Allman. All rights reserved. # Copyright (c) 1988, 1993 # The Regents of the University of California. All rights reserved. # # By using this file, you agree to the terms and conditions set # forth in the LICENSE file which can be found at the top level of # the sendmail distribution. # # divert(0) VERSIONID(`@(#)linux.m4 8.7 (Berkeley) 5/19/1998') define(`LOCAL_MAILER_PATH', /bin/mail.local)dnl OSTYPE(linux)dnl DOMAIN(generic)dnl MAILER(local)dnl MAILER(smtp)dnl
sendmail.cf using m4 m4/conf.m4 linux.mc >sendmail.cf
sendmail.cw in sendmail.cf (line 56)
mkdir -p /var/spool/mqueueBREAKPOINT" and rename to "JVM_BREAKPOINT" as it clashes with /usr/include/asm/s390-regs-common.h definition.config.sub as described previouslyCCFLAGS="-O1" CXXFLAGS="-O1" configure --host=s390-ibm-linux --with-shared
|
Applications |
|
|
Games |
|
|
fortune-mod-1.0-10 |
A program which will display a fortune. |
|
gnuchess-4.0.pl80-2 |
The GNU chess program. |
|
trojka-1.1-13 |
A non-X game of falling blocks. |
|
Graphics |
|
|
xbill-2.0-6 |
Stop Bill from loading his OS into all the computers. |
|
xloadimage-4.1-12 |
An X Window System based image viewer. |
|
xscreensaver-3.17-4 |
A set of X Window System screensavers. |
|
Archiving |
|
|
cpio-2.4.2-13 |
A GNU archiving program. |
|
dump-0.4b4-11 |
Programs for backing up and restoring filesystems. |
|
lha-1.00-11 |
An archiving and compression utility for LHarc format archives. |
|
ncompress-4.2.4-14 |
Fast compression and decompression utilities. |
|
rmt-0.4b4-11 |
Provides certain programs with access to remote tape devices. |
|
sharutils-4.2.1-1.6.1 |
The GNU shar utilities for packaging and unpackaging shell archives. |
|
tar-1.13.11-1 |
A GNU file archiving program. |
|
unarj-2.43-1 |
An uncompressor for .arj format archive files. |
|
unzip-5.40-1 |
A utility for unpacking zip files. |
|
zip-2.2-1 |
A file compression and packaging utility compatible with PKZIP. |
|
Communications |
|
|
getty_ps-2.0.7j-7 |
The getty and uugetty programs. |
|
lrzsz-0.12.20-2 |
The lrz and lsz modem communications programs. |
|
mgetty-1.1.21-2 |
A getty replacement for use with data and fax modems. |
|
mgetty-sendfax-1.1.21-2 |
Provides support for sending faxes over a modem. |
|
mgetty-viewfax-1.1.21-2 |
An X Window System fax viewer. |
|
mgetty-voice-1.1.21-2 |
A program for using your modem and mgetty as an answering machine. |
|
Database |
|
|
postgresql-6.5.3-3 |
The PostgreSQL server programs. |
|
postgresql-jdbc-6.5.3-3 |
The java-based client programs needed for accessing a PostgreSQL server. |
|
postgresql-odbc-6.5.3-3 |
The ODBC driver needed for accessing a PostgreSQL server. |
|
postgresql-perl-6.5.3-3 |
The perl-based client programs needed for accessing a PostgreSQL server. |
|
postgresql-python-6.5.3-3 |
The python-based client programs needed for accessing a PostgreSQL server. |
|
postgresql-server-6.5.3-3 |
The programs needed for a PostgreSQL server. |
|
postgresql-tcl-6.5.3-3 |
The tcl-based client programs needed for accessing a PostgreSQL server. |
|
postgresql-test-6.5.3-3 |
The test suite distributed with PostgreSQL. |
|
Editors |
|
|
THE-3.0-1 |
THE, The Hessling Editor. |
|
jed-0.98.7-2 |
A fast, compact editor based on the slang screen library. |
|
jed-common-0.98.7-2 |
Files needed by any Jed editor. |
|
jed-xjed-0.98.7-2 |
The X Window System version of the Jed text editor. |
|
joe-2.8-22 |
An easy to use, modeless text editor. |
|
vim-common-5.4-2 |
The common files needed by any version of the VIM editor. |
|
vim-enhanced-5.4-2 |
A version of the VIM editor which includes recent enhancements. |
|
vim-minimal-5.4-2 |
A minimal version of the VIM editor. |
|
Engineering |
|
|
bc-1.05a-4 |
GNU's bc (a numeric processing language) and dc (a calculator). |
|
units-1.55-3 |
A utility for converting amounts from one unit to another. |
|
File |
|
|
bzip2-0.9.5c-1 |
A file compression utility. |
|
file-3.27-3 |
A utility for determining file types. |
|
fileutils-4.0-8 |
The GNU versions of common file management utilities. |
|
findutils-4.1-32 |
The GNU versions of find utilities (find, xargs, and locate). |
|
git-4.3.17-5 |
A set of GNU Interactive Tools. |
|
gzip-1.2.4-14 |
The GNU data compression program. |
|
slocate-2.0-3 |
Finds files on a system via a central database. |
|
stat-1.5-11 |
A tool for finding out information about a specified file. |
|
tree-1.2-6 |
A utility which displays a tree view of the contents of directories. |
|
Internet |
|
|
elm-2.5.1-1 |
The elm mail user agent. |
|
fetchmail-5.1.0-1 |
A remote mail retrieval and forwarding utility. |
|
fetchmailconf-5.1.0-1 |
A utility for graphically configuring your fetchmail preferences. |
|
finger-0.10-25 |
The finger client and server. |
|
ftp-0.15-1 |
The standard UNIX FTP (File Transfer Protocol) client. |
|
fwhois-1.00-11 |
A finger-style whois program. |
|
ircii-4.4-7 |
An Internet Relay Chat (IRC) client. |
|
lynx-2.8.2-2 |
A text-based Web browser. |
|
mailx-8.1.1-9. |
The /bin/mail program, which is used to send mail via shell scripts |
|
metamail-2.7-22 |
A program for handling multimedia mail using the mailcap file. |
|
mutt-1.0pre3us-1 |
A text mode mail user agent. |
|
nc-1.10-4 |
Reads and writes data across network connections using TCP or UDP. |
|
ncftp-3.0beta19-2 |
An improved FTP client. |
|
nmh-1.0-2 |
A capable mail handling system with a command line interface. |
|
pine-4.10-3 |
A commonly used, MIME compliant mail and news reader. |
|
rsh-0.10-28 |
Clients and servers for remote access commands (rsh, rlogin, rcp). |
|
rsync-2.3.1-2 |
A program for synchronizing files over a network. |
|
slrn-0.9.5.7-2 |
A powerful, easy to use, threaded Internet news reader. |
|
slrn-pull-0.9.5.7-2 |
Offline news reading support for slrn. |
|
ssh-1.2.27-5iTO1 |
Secure Shell - encrypts network communications. |
|
ssh-clients-1.2.27-5iTO1 |
Clients for connecting to Secure Shell servers |
|
ssh-extras-1.2.27-5iTO1 |
Extra command for the secure shell protocol suite |
|
talk-0.11-3 |
Talk client for one-on-one Internet chatting. |
|
tcpdump-3.4-16 |
A network traffic monitoring tool. |
|
telnet-0.10-31 |
The client and server programs for the telnet remote login protocol. |
|
tin-1.4_990517-1 |
A basic Internet news reader. |
|
traceroute-1.4a5-16 |
Traces the route taken by packets over a TCP/IP network. |
|
trn-3.6-18 |
A news reader that displays postings in threaded format. |
|
urlview-0.7-4 |
A URL extractor/viewer for use with Mutt. |
|
w3c-libwww-apps-5.2.8-4 |
Applications built using Libwww web library: e.g. Robot, command line tool, etc. |
|
wget-1.5.3-5 |
A utility for retrieving files using the HTTP or FTP protocols. |
|
Multimedia |
|
|
libgr-progs-2.0.13-20 |
Tools for manipulating graphics files in libgr supported formats. |
|
libungif-progs-4.1.0-2 |
Programs for manipulating GIF format image files. |
|
transfig-3.2.1-3 |
A utility for converting FIG files (made by xfig) to other formats. |
|
xfig-3.2.2-7 |
An X Window System tool for drawing basic vector graphics. |
|
Publishing |
|
|
enscript-1.6.1-8 |
Converts plain ASCII to PostScript. |
|
freetype-utils-1.2-7. |
Several utilities to manipulate and examine TrueType fonts |
|
ghostscript-5.10-10 |
A PostScript(TM) interpreter and renderer. |
|
groff-1.11a-9 |
A document formatting system. |
|
groff-gxditview-1.11a-9 |
An X previewer for groff text processor output. |
|
lout-3.08-7 |
The Lout document formatting language. |
|
lout-doc-3.08-7 |
The documentation for the Lout document formatting language. |
|
mpage-2.4-7 |
A tool for printing multiple pages of text on each printed page. |
|
rhs-printfilters-1.57-3 |
Red Hat print filters, for use with the printtool. |
|
texinfo-3.12h-2 |
Tools needed to create Texinfo format documentation files. |
|
xpdf-0.90-1 |
A PDF file viewer for the X Window System. |
|
System |
|
|
arpwatch-2.1a4-16 |
Network monitoring tools for tracking IP addresses on a network. |
|
bind-utils-8.2.2_P3-1 |
DNS utilities: host, dig, dnsquery, and nslookup. |
|
dialog-0.6-14 |
A utility for creating TTY dialog boxes. |
|
dosfstools-2.2-1 |
A program which creates MS-DOS FAT filesystems on Linux systems. |
|
ipxutils-2.2.0.16.a-1 |
Tools for configuring and debugging IPX interfaces and networks. |
|
knfsd-clients-1.4.7-7 |
Clients for connecting to a remote NFS server. |
|
linuxconf-1.16r10-2 |
An extremely capable system configuration tool. |
|
macutils-2.0b3-12 |
Utilities for manipulating Macintosh file formats. |
|
mtools-3.9.1-5 |
Programs for accessing MS-DOS disks without mounting the disks. |
|
ncpfs-2.2.0.16.a-1 |
Utilities for the ncpfs filesystem, a NetWare client for Linux. |
|
procinfo-17-1 |
A tool for gathering and displaying system information. |
|
procps-2.0.4-2 |
Utilities for monitoring your system and processes on your system. |
|
procps-X11-2.0.4-2 |
An X based system message monitoring utility. |
|
psacct-6.3-10 |
Utilities for monitoring process activities. |
|
psmisc-18-3 |
Utilities for managing processes on your system. |
|
rdate-0.960923-8 |
Retrieving the date and time from another machine on your network. |
|
rdist-6.1.5-11 |
Maintains identical copies of files on multiple machines. |
|
rhmask-1.0-6 |
Generates and restores mask files based on original and update files. |
|
rpm2html-1.2-4 |
Translates an RPM database and dependency information into HTML. |
|
rpmfind-1.2-4 |
Finds and transfers RPM files for a specified program. |
|
samba-client-2.0.5a-12 |
Samba (SMB) client programs. |
|
samba-common-2.0.5a-12 |
Files used by both Samba servers and clients. |
|
screen-3.9.4-3 |
A screen manager that supports multiple logins on one terminal. |
|
symlinks-1.2-5 |
A utility which maintains a system's symbolic links. |
|
time-1.7-9 |
A GNU utility for monitoring a program's use of system resources. |
|
timeconfig-3.0-5 |
Text mode tools for setting system time parameters. |
|
ucd-snmp-utils-4.0.1-4 |
Network management utilities using SNMP, from the UCD-SNMP project. |
|
which-2.8-1 |
Displays where a particular program in your path is located. |
|
xosview-1.7.1-2 |
An X Window System utility for monitoring system resources. |
|
xsysinfo-1.7-1 |
An X Window System kernel parameter monitoring tool. |
|
Text |
|
|
diffutils-2.7-16 |
A GNU collection of diff utilities. |
|
ed-0.2-12 |
The GNU line editor. |
|
gawk-3.0.4-1 |
The GNU version of the awk text processing utility. |
|
grep-2.3-2 |
The GNU versions of grep pattern matching utilities. |
|
indent-2.2.0-1 |
A GNU program for formatting C code. |
|
less-340-1 |
A text file browser similar to more, but better. |
|
m4-1.4-12 |
The GNU macro processor. |
|
rgrep-0.98.7-2 |
A grep utility which can recursively descend through directories. |
|
sed-3.02-4 |
A GNU stream text editor. |
|
textutils-2.0-2 |
A set of GNU text file modifying utilities. |
|
Development |
|
|
Debuggers |
|
|
gdb-4.18-4 |
A GNU source-level debugger for C, C++ and Fortran. |
|
lslk-1.19-5 |
A lock file lister. |
|
lsof-4.45-1 |
Lists files open by processes |
|
strace-3.99.1-2 |
Tracks and displays system calls associated with a running process. |
|
Languages |
|
|
Regina-0.08h-1 |
Regina Rexx Interpreter |
|
Regina-devel-0.08h-1 |
Regina Developement library and headers |
|
cpp-2.95.1-24 |
The GNU C-Compatible Compiler Preprocessor. |
|
cpp-2.95.1-25 |
The GNU C-Compatible Compiler Preprocessor. |
|
expect-5.28-30 |
A tcl extension for simplifying program-script interaction. |
|
gcc-2.95.1-25 |
The GNU Compiler Collection. |
|
gcc-c++-2.95.1-25 |
C++ support for the gcc compiler. |
|
gcc-g77-2.95.1-25 |
Fortran 77 support for the gcc compiler. |
|
gcc-objc-2.95.1-25 |
Objective C support for the gcc compiler. |
|
guile-1.3-7 |
A GNU implementation of Scheme for application extensibility. |
|
itcl-3.0.1-30 |
Object oriented mega widgets for tcl |
|
p2c-1.22-3 |
A Pascal to C translator. |
|
p2c-devel-1.22-3 |
Files for p2c Pascal to C translator development. |
|
perl-5.00503-6 |
The Perl programming language. |
|
python-1.5.2-7 |
An interpreted, interactive object-oriented programming language. |
|
tcl-8.0.5-30 |
An embeddable scripting language. |
|
tclx-8.0.5-30 |
Tcl/Tk extensions for POSIX systems. |
|
tix-4.1.0.6-30 |
A set of capable widgets for Tk. |
|
tk-8.0.5-30 |
Tk GUI toolkit for Tcl, with shared libraries |
|
tkinter-1.5.2-7 |
A graphical user interface for the Python scripting language. |
|
umb-scheme-3.2-9 |
An implementation of the Scheme programming language. |
|
Libraries |
|
|
ORBit-devel-0.5.0-2 |
Development libraries, header files and utilities for ORBit. |
|
XFree86-devel-3.3.5-3 |
X11R6 static libraries, headers and programming man pages. |
|
apache-devel-1.3.9-8 |
Development tools for the Apache Web server. |
|
audiofile-devel-0.1.9-2 |
Libraries, includes and other files to develop audiofile applications. |
|
bind-devel-8.2.2_P3-1 |
Include files and libraries needed for bind DNS development. |
|
e2fsprogs-devel-1.17-1 |
Ext2 filesystem-specific static libraries and headers. |
|
esound-devel-0.2.17-1 |
Development files for EsounD applications. |
|
freetype-devel-1.2-7 |
Header files and static library for development with FreeType. |
|
gd-devel-1.7.3-1 |
Header files and libraries needed for gd development |
|
gd-devel-1.3-5 |
The development libraries and header files for gd. |
|
gdbm-devel-1.8.0-2 |
Development libraries and header files for the gdbm library. |
|
glib-devel-1.2.5-1 |
The GIMP ToolKit (GTK+) and GIMP Drawing Kit (GDK) support library. |
|
glibc-devel-2.1.2-1 |
Header and object files for development using standard C libraries. |
|
gmp-devel-2.0.2-10 |
Development tools for the GNU MP arbitrary precision library. |
|
gpm-devel-1.17.9-3 |
Libraries and header files for developing mouse driven programs. |
|
guile-devel-1.3-7 |
Libraries and header files for the GUILE extensibility library. |
|
inn-devel-2.2.1-1 |
The INN (InterNetNews) library. |
|
libghttp-devel-1.0.4-1 |
GNOME http client development |
|
libgr-devel-2.0.13-20 |
Development tools for programs which will use the libgr library. |
|
libpcap-0.4-16 |
A system-independent interface for user-level packet capture. |
|
libpng-devel-1.0.3-4 |
Development tools for programs to manipulate PNG image format files. |
|
libtermcap-devel-2.0.8-18 |
Development tools for programs which will access the termcap database. |
|
libtiff-devel-3.5.4-1 |
Development tools for programs which will use the libtiff library. |
|
libungif-devel-4.1.0-2 |
Development tools for programs which will use the libungif library. |
|
libxml-devel-1.7.3-1 |
Libraries, includes and other files to develop libxml applications. |
|
linuxconf-devel-1.16r10-2 |
The tools needed for developing linuxconf modules. |
|
ncurses-devel-4.2-25 |
The development files for applications which use ncurses. |
|
newt-devel-0.50-13 |
Newt windowing toolkit development files. |
|
postgresql-devel-6.5.3-3 |
PostgreSQL development header files and libraries. |
|
python-devel-1.5.2-7 |
The libraries and header files needed for Python development. |
|
readline-devel-2.2.1-5 |
Development files for programs which will use the readline library. |
|
rpm-devel-3.0.3-3 |
Development files for applications which will manipulate RPM packages. |
|
slang-devel-1.2.2-4 |
The static library and header files for development using S-Lang. |
|
socks5-devel-v1.0r10-1TO |
Static library and includes for socksifying clients. |
|
ucd-snmp-devel-4.0.1-4 |
The development environment for the UCD-SNMP project. |
|
w3c-libwww-devel-5.2.8-4 |
Libraries and header files for programs that use libwww. |
|
xpm-devel-3.4k-1 |
Tools for developing apps which will use the XPM pixmap library. |
|
zlib-devel-1.1.3-5 |
Header files and libraries for developing apps which will use zlib. |
|
System |
|
|
kernel-headers-2.2.14-4 |
Header files for the Linux kernel. |
|
kernel-source-2.2.14-4 |
The source code for the Linux kernel. |
|
Tools |
|
|
binutils-2.9.1.0.23-6 |
A GNU collection of binary utilities. |
|
bison-1.28-1 |
A GNU general-purpose parser generator. |
|
byacc-1.9-11 |
A public domain Yacc parser generator. |
|
cdecl-2.5-9 |
Programs for encoding and decoding C and C++ function declarations. |
|
cproto-4.6-2 |
Generates function prototypes and variable declarations from C code. |
|
ctags-3.2-1 |
A C programming language indexing and/or cross-reference tool. |
|
cvs-1.10.6-2 |
A version control system. |
|
diffstat-1.27-1 |
A utility which provides statistics based on the output of diff. |
|
flex-2.5.4a-7 |
A tool for creating scanners (text pattern recognizers). |
|
gettext-0.10.35-13 |
GNU libraries and utilities for producing multi-lingual messages. |
|
gperf-2.7-5 |
A perfect hash function generator. |
|
make-3.77-6 |
A GNU tool which simplifies the build process for users. |
|
patch-2.5-10 |
The GNU patch command, for modifying/upgrading files. |
|
pmake-2.1.33-5 |
The BSD 4.4 version of make. |
|
pmake-customs-2.1.33-5 |
A remote execution facility for pmake. |
|
python-tools-1.5.2-7 |
A collection of development tools included with Python. |
|
rcs-5.7-10 |
Revision Control System (RCS) file version management tools. |
|
Networking |
|
|
Daemons |
|
|
socks5-server-v1.0r10-1TO |
Socks server (socks5) for forwarding sockets to remote hosts. |
|
System Environment |
|
|
Base |
|
|
SysVinit-2.77-2 |
Programs which control basic system processes. |
|
adjtimex-1.3-6 |
A utility for adjusting kernel time variables. |
|
authconfig-2.0-2 |
Text-mode tool for setting up NIS and shadow passwords. |
|
chkconfig-1.0.7-2 |
A system tool for maintaining the /etc/rc.d hierarchy. |
|
chkfontpath-1.5-1 |
Simple interface for editing the font path for the X font server. |
|
dev-2.7.10-6 |
The most commonly-used entries in the /dev directory. |
|
e2fsprogs-1.17-1 |
Utilities for managing the second extended (ext2) filesystem. |
|
genromfs-0.3-4 |
Tool for creating romfs filesystems. |
|
info-3.12h-2 |
A stand-alone TTY-based reader for GNU texinfo documentation. |
|
initscripts-4.48-2 |
The inittab file and the /etc/rc.d scripts. |
|
ipchains-1.3.9-3 |
Tools for managing Linux kernel packet filtering capabilities. |
|
ipvsadm-1.1-2 |
Administration tool for Virtual Server |
|
ldconfig-1.9.5-15 |
Creates a shared library cache and maintains symlinks for ld.so. |
|
logrotate-3.3-1 |
Rotates, compresses, removes and mails system log files. |
|
losetup-2.9u-4 |
Programs for setting up and configuring loopback devices. |
|
man-1.5g-6 |
A set of documentation tools: man, apropos and whatis. |
|
mingetty-0.9.4-10 |
A compact getty program for virtual consoles only. |
|
mktemp-1.5-1 |
A small utility for safely making /tmp files. |
|
mount-2.9u-4 |
Programs for mounting and unmounting filesystems. |
|
net-tools-1.53-1 |
The basic tools for setting up networking. |
|
ntsysv-1.0.7-2 |
A system tool for maintaining the /etc/rc.d hierarchy. |
|
osa2lan-2.2.13-1 |
IBM osa2lan network driver |
|
pam-0.68-7 |
A security tool which provides authentication for applications. |
|
passwd-0.63-1 |
The passwd utility for setting/changing passwords using PAM. |
|
pwdb-0.60-1 |
The password database library. |
|
quota-1.66-9 |
System administration tools for monitoring users' disk usage. |
|
rpm-3.0.3-3 |
The Red Hat package management system. |
|
s390utils-0.2-2 |
Linux/390 specific utilities. |
|
shadow-utils-19990827-2 |
Utilities for managing shadow password files and user/group accounts. |
|
termcap-9.12.6-15 |
The terminal feature database used by certain applications. |
|
tmpwatch-2.0-1 |
A utility for removing files based on when they were last accessed. |
|
utempter-0.5.1-2 |
A privileged helper for utmp/wtmp updates. |
|
util-linux-2.9w-24 |
A collection of basic system utilities. |
|
vixie-cron-3.0.1-39 |
The Vixie cron daemon for executing specified programs at set |
|
yp-tools-2.3-2 |
NIS (or YP) client programs. |
|
Daemons |
|
|
ORBit-0.5.0-2 |
A high-performance CORBA Object Request Broker. |
|
XFree86-xfs-3.3.5-3 |
A font server for the X Window System. |
|
am-utils-6.0.1-4 |
Automount utilities including an updated version of Amd. |
|
anonftp-2.8-1 |
A program which enables anonymous FTP access. |
|
apache-1.3.9-8 |
The most widely used Web server on the Internet. |
|
at-3.1.7-11 |
Job spooling tools. |
|
autofs-3.1.3-9 |
A tool for automatically mounting and unmounting filesystems. |
|
bdflush-1.5-10 |
The process which starts the flushing of dirty buffers back to disk. |
|
bind-8.2.2_P3-1 |
A DNS (Domain Name System) server. |
|
comsat-0.15-1 |
A mail checker client and the comsat mail checking server. |
|
dhcpcd-1.3.17pl5-2 |
DHCPC Daemon |
|
esound-0.2.17-1 |
Allows several audio streams to play on a single audio device. |
|
gated-3.5.10-10 |
The GateD routing daemon. |
|
gpm-1.17.9-3 |
A mouse server for the Linux console. |
|
imap-4.5-4 |
Server daemons for IMAP and POP network mail protocols. |
|
inews-2.2.1-1 |
Sends Usenet articles to a local news server for distribution. |
|
inn-2.2.1-1 |
The InterNetNews (INN) system, an Usenet news server. |
|
intimed-1.10-9 |
A time server for synchronizing networked machines' clocks. |
|
knfsd-1.4.7-7 |
The kernel NFS server. |
|
lpr-0.48-1 |
A utility that manages print jobs. |
|
mars-nwe-0.99pl17-4 |
NetWare file and print servers which run on Linux systems. |
|
mcserv-4.5.40-2 |
Server for the Midnight Commander network file management system. |
|
mod_perl-1.21-2 |
A Perl interpreter for the Apache Web server. |
|
mod_php-2.0.1-9 |
The PHP/FI PHP language module for the Apache Web server. |
|
mod_php3-3.0.9-1 |
The PHP3 HTML-embedded scripting language for use with Apache. |
|
mod_php3-imap-3.0.9-1 |
IMAP module for PHP3. |
|
mod_php3-manual-3.0.9-1 |
On-line manual for PHP3 |
|
mod_php3-pgsql-3.0.9-1 |
PostgreSQL database module for PHP3. |
|
netkit-base-0.10-37 |
The ping and inetd networking programs. |
|
nscd-2.1.2-1 |
A Name Service Caching Daemon (nscd). |
|
php-3.0.12-7 |
The PHP HTML-embedded scripting language for use with Apache. |
|
php-imap-3.0.12-7 |
IMAP module for PHP3. |
|
php-ldap-3.0.12-7 |
LDAP directory module for PHP3. |
|
php-manual-3.0.12.7 |
On-line manual for PHP3 |
|
php-pgsql-3.0.12-7 |
PostgreSQL database module for PHP3. |
|
pidentd-3.0.7-5 |
An implementation of the RFC1413 identification server. |
|
portmap-4.0-17 |
A program which manages RPC connections. |
|
postfix-19991231_pl02-3 |
Postfix Mail Transport Agent |
|
procmail-3.13.1-4 |
The procmail mail processing program. |
|
pump-0.7.2-2 |
Bootp and dhcp client for automatic IP configuration |
|
rusers-0.15-6 |
Displays the users logged into machines on the local network. |
|
rwall-0.10-23 |
Client and server for sending messages to a host's logged in users. |
|
rwho-0.15-2 |
Displays who is logged in to local network machines. |
|
samba-2.0.5a-12 |
Samba SMB server. |
|
sendmail-8.9.3-15 |
A widely used Mail Transport Agent (MTA). |
|
sendmail-cf-8.9.3-15 |
The files needed to reconfigure Sendmail. |
|
ssh-server-1.2.27-5iTO1 |
Secure Shell protocol server (sshd) |
|
sysklogd-1.3.31-14 |
System logging and kernel message trapping daemons. |
|
tcp_wrappers-7.6-9 |
A security tool which acts as a wrapper for TCP daemons. |
|
tftp-0.15-1 |
The client and server for the Trivial File Transfer Protocol (TFTP). |
|
timed-0.10-23 |
Programs for maintaining networked machines' time synchronization. |
|
ucd-snmp-4.0.1-4 |
A collection of SNMP protocol tools from UC-Davis. |
|
wu-ftpd-2.5.0-9 |
An FTP daemon provided by Washington University. |
|
xntp3-5.93-13 |
Synchronizes system time using the Network Time Protocol (NTP). |
|
ypbind-3.3-24 |
The NIS daemon which binds NIS clients to an NIS domain. |
|
ypserv-1.3.9-1 |
The NIS (Network Information Service) server. |
|
Kernel |
|
|
kernel-IPLtape-2.2.14-4 |
The Linux SMP kernel for IPL from a /390 tape unit. |
|
kernel-IPLvrdr-2.2.14-4 |
The Linux SMP kernel for IPL from virtual VM reader. |
|
kernel-utils-2.2.14-4 |
Kernel related utilities. |
|
modutils-2.1.121-15 |
The kernel daemon (kerneld) and kernel module utilities. |
|
Libraries |
|
|
XFree86-libs-3.3.5-3 |
Shared libraries needed by the X Window System version 11 release 6. |
|
audiofile-0.1.9-2 |
A library for accessing various audio file formats. |
|
cracklib-2.7-5 |
A password-checking library. |
|
cracklib-dicts-2.7-5 |
The standard CrackLib dictionaries. |
|
freetype-1.2-7 |
Free TrueType font rasterizer library. |
|
gd-1.3-5 |
A graphics library for drawing .gif files. |
|
gd-1.7.3-1 |
PNG manipulating library |
|
gdbm-1.8.0-2 |
A GNU set of database routines which use extensible hashing. |
|
glib-1.2.5-1 |
A library of handy utility functions. |
|
glibc-2.1.2-1 |
The GNU libc libraries. |
|
gmp-2.0.2-10 |
A GNU arbitrary precision library. |
|
libPropList-0.8.3-2 |
PL ensures compatibility of programs' configuration or preference files with GNUstep/OPENSTEP. |
|
libelf-0.6.4-4 |
An ELF object file access library. |
|
libghttp-1.0.4-1 |
GNOME http client library. |
|
libgr-2.0.13-20 |
A library for handling different graphics file formats. |
|
libpng-1.0.3-4 |
A library of functions for manipulating PNG image format files. |
|
libstdc++-2.95.1-25 |
The Standard C++ library. |
|
libstdc++-2.95.1-24 |
The Standard C++ library. |
|
libtermcap-2.0.8-18 |
A basic system library for accessing the termcap database. |
|
libtiff-3.5.4-1 |
A library of functions for manipulating TIFF format image files. |
|
libungif-4.1.0-2 |
A library for manipulating GIF format image files. |
|
libxml-1.7.3-1 |
An XML library. |
|
ncurses-4.2-25 |
A CRT screen handling and optimization package. |
|
newt-0.50-13 |
A development library for text mode user interfaces. |
|
popt-1.4-1 |
A C library for parsing command line parameters. |
|
readline-2.2.1-5 |
A library for reading and returning lines from a terminal. |
|
slang-1.2.2-4 |
The shared library for the S-Lang extension language. |
|
w3c-libwww-5.2.8-4 |
HTTP library of common code |
|
xpm-3.4k-1 |
A pixmap library for the X Window System. |
|
zlib-1.1.3-5 |
The zlib compression and decompression library. |
|
Shells |
|
|
ash-0.2-18 |
A smaller version of the Bourne shell. |
|
bash-1.14.7-16 |
The GNU Bourne Again shell (bash). |
|
bash2-2.03-6 |
The GNU Bourne Again shell (bash). |
|
mc-4.5.40-2 |
A user-friendly file manager and visual shell. |
|
pdksh-5.2.14-1 |
A public domain clone of the Korn shell (ksh). |
|
sash-3.3-1 |
A statically linked shell, including some built-in basic commands. |
|
sh-utils-2.0-1 |
A set of GNU utilities commonly used in shell scripts. |
|
tcsh-6.08.00-6 |
An enhanced version of csh, the C shell. |
|
zsh-3.0.5-15 |
A shell similar to ksh, but with improvements. |
|
User Interface |
|
|
X |
|
|
X11R6-contrib-3.3.2-6 |
A collection of user-contributed X Window System programs. |
|
XFree86-3.3.5-3 |
The basic fonts, programs and docs for an X workstation. |
|
XFree86-100dpi-fonts-3.3.5-3 |
X Window System 100dpi fonts. |
|
XFree86-75dpi-fonts-3.3.5-3 |
A set of 75 dpi resolution fonts for the X Window System. |
|
XFree86-cyrillic-fonts-3.3.5-3 |
Cyrillic fonts for X. |
|
x3270-3.1.1.6-8 |
An X Window System based IBM 3278/3279 terminal emulator. |
|
X Hardware Support |
|
|
XFree86-Xnest-3.3.5-3 |
A nested XFree86 server. |
|
XFree86-Xvfb-3.3.5-3 |
A virtual framebuffer X Windows System server for XFree86. |